Software Development with AI: Tools, Patterns, and Real-World Workflows
When you're building software today, software development, the process of designing, coding, testing, and deploying applications. Also known as app development, it's no longer just about writing code—it's about working alongside AI tools that help you ship faster, avoid mistakes, and handle complexity without drowning in it. The old way—writing everything by hand, debugging for hours, and guessing how your app will behave under load—is fading. Now, developers use AI to generate code, manage APIs, and even enforce security rules before a single line runs in production.
vibe coding, a workflow where AI assists in real-time during development, often using tools like Cursor.sh or Wasp is changing how teams build features. Instead of spending weeks on architecture diagrams, you focus on one small, end-to-end feature at a time—what’s called a vertical slice, a complete, working piece of functionality from UI to database. This isn’t just faster—it’s smarter. You test real user flows early, catch bugs before they spread, and avoid over-engineering. And when you’re building SaaS apps, you can’t ignore multi-tenancy, the ability to serve multiple customers from the same codebase while keeping their data completely separate. Get this wrong, and you risk data leaks, billing chaos, or compliance fines.
Then there’s the problem of vendor lock-in. If you build your app to work only with OpenAI, what happens when prices change or the API goes down? That’s where LLM interoperability, using patterns like LiteLLM or LangChain to switch between AI providers without rewriting your code comes in. It’s not a luxury—it’s a survival tactic. Teams that abstract their AI layer can swap models in minutes, test cheaper alternatives, and keep costs under control. And when you’re using AI to call external tools—like databases, payment systems, or calendars—you need function calling, a way to let LLMs trigger real actions instead of guessing or hallucinating answers. Without it, your app will give you confident, wrong answers.
None of this matters if your team can’t onboard new people. Vibe-coded codebases often have unwritten rules—patterns only the original builders know. That’s why successful teams create onboarding playbooks, living guides that walk new devs through the real workflow, not just the docs. It’s not about perfect documentation. It’s about capturing how things actually work. And when you measure success, you don’t count lines of code or bug tickets. You look at quality, speed, and whether the feature actually moved the business needle.
What you’ll find below isn’t theory. These are real, battle-tested approaches from developers who’ve been there—building AI-powered apps that work under pressure, stay secure, and actually get used. Whether you’re just starting with AI tools or trying to scale a team that’s already using them, the posts here give you the exact steps, pitfalls to avoid, and patterns that make the difference between chaos and control.

Post-Training Quantization for Large Language Models: 8-Bit and 4-Bit Methods Explained
Post-training quantization cuts LLM memory use and speeds up inference by 2-3x without retraining. Learn how 8-bit and 4-bit methods like SmoothQuant, AWQ, and GPTQ make it possible-and what you need to know to use them.
Read More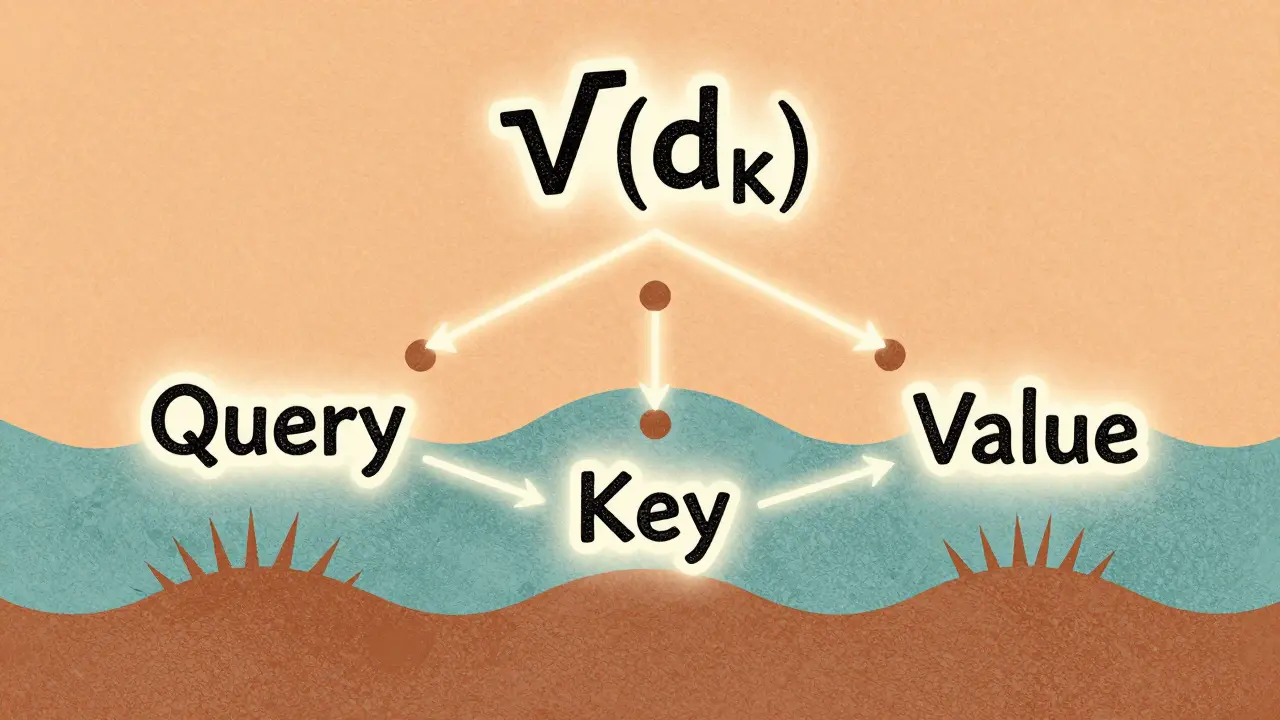
Scaled Dot-Product Attention Explained for Large Language Model Practitioners
Scaled dot-product attention is the core mechanism behind modern LLMs like GPT and Llama. Learn why the 1/√(d_k) scaling is non-negotiable, how it prevents training collapse, and what pitfalls to avoid in practice.
Read More
Ethical AI Agents for Code: How Guardrails Enforce Policy by Default
Ethical AI agents for code are designed to refuse illegal or unethical commands by default, using policy-as-code architecture to enforce compliance without human intervention. This approach is becoming the new standard for trustworthy AI in government, finance, and development.
Read More
Safety by Design in Generative AI: How to Embed Protections into Product Architecture
Safety by Design embeds child protection and harm prevention directly into generative AI architecture-from training data to real-time filtering. This isn't optional. It's the only way to build AI that doesn't become a weapon.
Read More
Data Augmentation for LLM Fine-Tuning: Synthetic and Human-in-the-Loop Approaches
Data augmentation boosts LLM fine-tuning by generating realistic training examples using synthetic methods and human feedback. Learn how synthetic data and human-in-the-loop approaches improve accuracy, reduce costs, and work with LoRA for efficient model adaptation.
Read More
Prompt Compression: How to Reduce Tokens Without Losing LLM Accuracy
Prompt compression cuts LLM token usage by up to 80% without losing accuracy, slashing costs and latency. Learn how techniques like LLMLingua work, where they excel, and how to implement them today.
Read More
Why Large Language Models Outperform Task-Specific Systems on Many NLP Tasks
Large language models outperform task-specific NLP systems on complex, context-heavy tasks due to their scale, architecture, and ability to generalize. But for simple, domain-specific tasks, traditional models still win on accuracy and efficiency.
Read More
Multi-Task Fine-Tuning for Large Language Models: One Model, Many Skills
Multi-task fine-tuning lets one large language model master multiple skills at once, outperforming single-task models with less compute. Learn how it works, why it’s beating GPT-4 on benchmarks, and how companies are using it in 2026.
Read More
SAST, DAST, and SCA for AI-Generated Code: Tools That Actually Catch Real Security Issues
SAST, DAST, and SCA tools must adapt to catch security flaws in AI-generated code. Learn how modern tools like Mend and Cycode now detect vulnerabilities in AI-written code, why traditional DAST is obsolete, and how to build a layered defense that actually works.
Read More
Curriculum Learning in NLP: How Ordering Data Makes Large Language Models Smarter
Curriculum learning in NLP improves large language models by training them on data ordered from simple to complex, cutting costs, speeding up training, and boosting accuracy on hard tasks. Learn how it works and where it shines.
Read More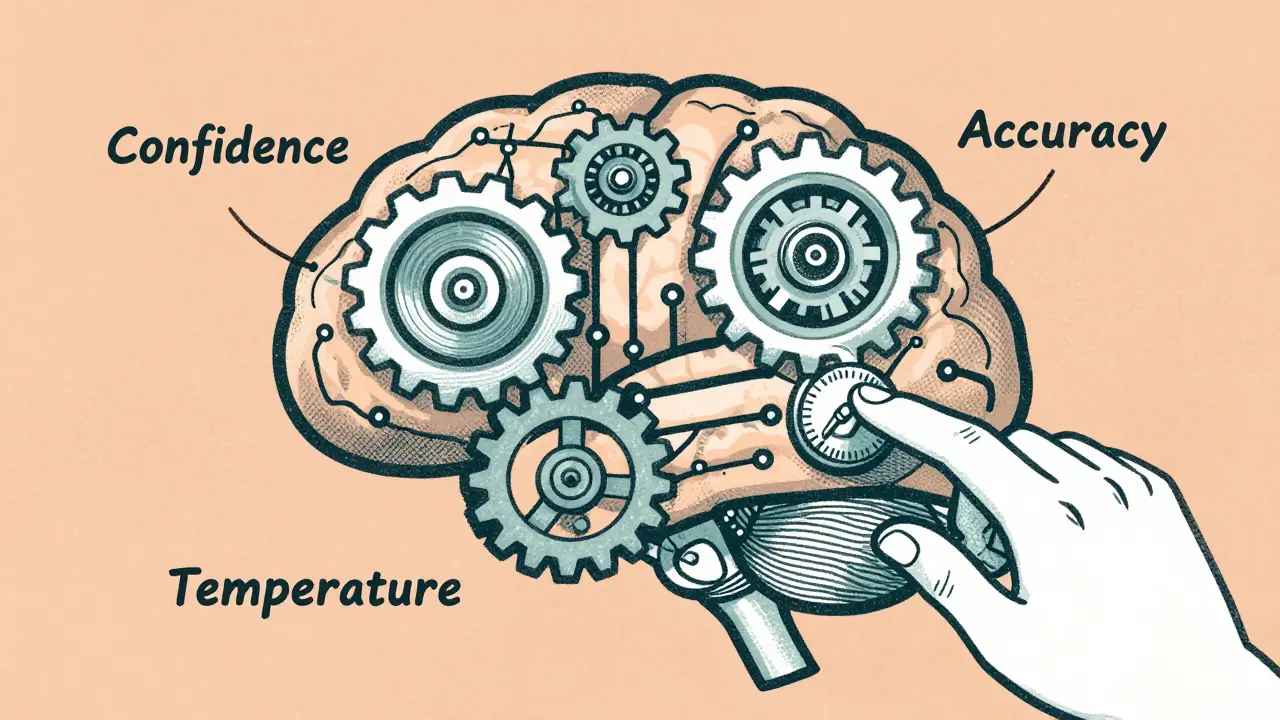
Post-Training Calibration for Large Language Models: How Confidence and Abstention Improve Reliability
Post-training calibration ensures large language models express confidence accurately and know when to abstain. Learn how it works, why it matters, and how to apply it to improve reliability without retraining.
Read More
Batched Generation in LLM Serving: How Request Scheduling Impacts Outputs
Batched generation in LLM serving uses dynamic request scheduling to boost throughput by 3-5x. Learn how continuous batching, PagedAttention, and learning-to-rank algorithms make AI responses faster and cheaper - and why most systems still get it wrong.
Read More