
When you ask a chatbot a question, generate an image, or even get autocomplete suggestions while typing, you’re interacting with models that were trained using one of three core pretraining methods: masked modeling, next-token prediction, or denoising. These aren’t just buzzwords-they’re the foundational techniques that let AI models learn from raw data without human labels. And understanding how they work changes everything about how you think about AI.
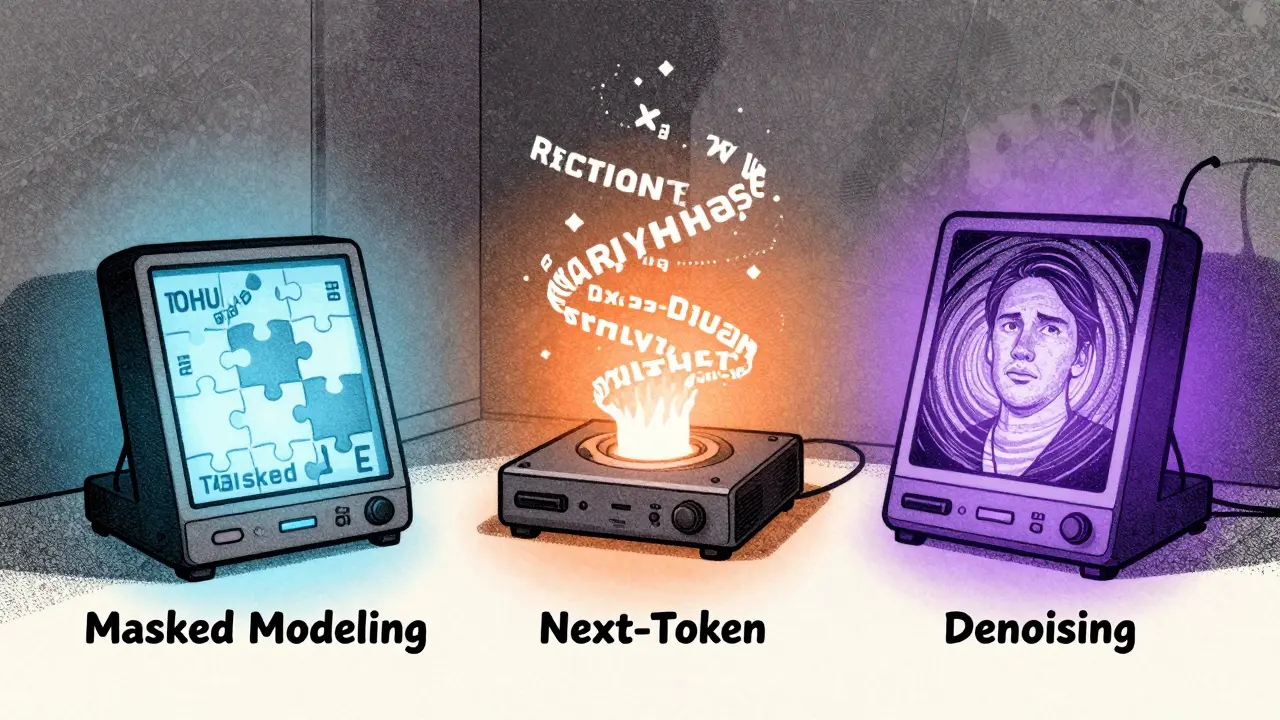
Masked Modeling: Learning by Filling in the Blanks
Imagine reading a sentence like: "The cat sat on the ___" and being asked to guess the missing word. That’s masked modeling in action. Developed by Google researchers behind BERT in 2018, this method randomly hides 15% of words or tokens in a text passage and trains the model to predict them using context from both before and after the gap. Unlike earlier models that only looked left-to-right, BERT’s bidirectional approach let it understand that "The cat sat on the mat" and "The cat sat on the chair" are both valid, because it saw the whole context.
This technique excels at understanding language. Models like BERT and RoBERTa dominate tasks like question answering, sentiment analysis, and named entity recognition. On the SQuAD 2.0 benchmark, BERT-large achieves 88.5% accuracy in finding answers in paragraphs-a number that’s held up for years. It’s why Google Search uses BERT to understand complex queries like "Can I use a bicycle helmet for skiing?" instead of just matching keywords.
But masked modeling has limits. It doesn’t naturally generate text. If you force it to predict sequences one token at a time, it gets confused. The model learns to fill gaps, not to build sentences from scratch. That’s why you won’t find a chatbot powered purely by BERT-it needs fine-tuning or a separate generation head to even attempt conversation. And when trained on long documents, it struggles with coherence beyond 100 tokens. It’s a brilliant understanding engine, but not a storyteller.
Next-Token Prediction: The Power of Predicting What Comes Next
Next-token prediction is simpler in concept but more powerful in scale. Think of it as the AI version of autocomplete on steroids. Given the sentence "The sun rises in the," the model predicts the next word: "east." Then it takes that prediction, adds it to the input, and predicts the next word after that. Repeat this thousands of times, and you get a fluent, coherent text generator.
This is the backbone of OpenAI’s GPT series. GPT-3, with 175 billion parameters, learned to predict the next token across trillions of words from books, websites, and code. The result? It can write essays, debug code, and even mimic Shakespeare. On the SuperGLUE benchmark, GPT-3 scored 76.2% accuracy-a leap over previous models. And because it generates text naturally, it’s become the default choice for chatbots, content tools, and customer service bots.
But there’s a catch. Since it only looks backward-not forward-it misses context. A model might say, "The sky is blue because it reflects the ocean," because it learned that phrase from training data, even though it’s scientifically wrong. It doesn’t understand; it predicts patterns. And in long conversations, errors pile up. After 500 tokens, accuracy drops by 37% because each wrong prediction changes the context for the next one.
Still, its scalability is unmatched. GPT-3 required over 3640 PetaFLOP/s-days of compute. That’s more than 1.5 million hours on a single V100 GPU. But now, smaller versions like GPT-2-small can be trained in 16 GPU days. And with 78% of enterprise LLM deployments using this method (Gartner, 2024), it’s the most widely adopted pretraining objective today.
Denoising: Rebuilding Images from Noise
If masked modeling and next-token prediction are about text, denoising is about images-and it’s revolutionized AI art. Developed in 2020 by researchers behind DDPM (Denoising Diffusion Probabilistic Models), this method doesn’t try to guess what’s missing. Instead, it starts with pure noise-a random mess of pixels-and learns to slowly remove noise step by step until a clear image emerges.
Think of it like cleaning a dirty window. You don’t know what’s underneath, so you start with a completely fogged pane. Then, over 1,000 tiny steps, the model learns to reverse the fogging process. Train it on millions of images, and suddenly it can generate a photorealistic cat wearing sunglasses, or a futuristic cityscape in the style of Van Gogh.
Denoising powers Stable Diffusion, DALL-E 2, and Midjourney. On the CIFAR-10 dataset, these models achieve FID scores as low as 1.79-a metric that measures realism. Human evaluators prefer denoised images 72.1% of the time over those from older GANs. And with 92% of AI image tools using this method (Statista, 2024), it’s the clear leader in visual generation.
But it’s expensive. Generating a single 1024x1024 image can take 24GB of VRAM and 30 seconds on an A100 GPU. Training a full model takes 15-30 days on 64 high-end GPUs. And while it’s great at generating images, it’s terrible at rendering text within them-something users consistently complain about. That’s why you’ll see gibberish words on signs in AI-generated street scenes.

Comparing the Three: Strengths, Weaknesses, and Use Cases
Here’s how they stack up side by side:
| Objective | Best For | Key Strength | Major Weakness | Typical Use Case |
|---|---|---|---|---|
| Masked Modeling | Text understanding | Bidirectional context; excels at reasoning | Cannot generate text natively | Search engines, question answering, entity extraction |
| Next-Token Prediction | Text generation | Fluent, scalable, natural output | Error accumulation; no backward context | Chatbots, content writing, code generation |
| Denoising | Image and audio generation | High-fidelity, detailed outputs | Extremely slow; high compute cost | AI art, photo editing, medical imaging |
Each method has its niche. Masked modeling wins when you need deep understanding-like pulling dates, names, or relationships from legal documents. Next-token prediction dominates when you need fluent output-like drafting emails or answering customer questions. Denoising leads when quality matters more than speed-like creating marketing visuals or simulating MRI scans.
What’s Next? Hybrid Approaches Are Taking Over
The future isn’t about choosing one. It’s about mixing them. Google’s Gemini 2.0, released in late 2024, combines masked modeling and next-token prediction in a single model. The result? A 90.1% score on the MMLU benchmark, outperforming pure next-token models by 5.7 points. Meta’s Llama 3 introduced dynamic masking, adjusting how many tokens get hidden during training to improve efficiency. And Stability AI’s Stable Diffusion 3 cut denoising steps from 50 to just 4 by using flow matching-a technique borrowed from physics.
Researchers are now experimenting with hybrid objectives that do all three at once. OpenAI’s upcoming "Project Orion" (Q3 2025) aims to unify text and image pretraining under one framework. Meanwhile, academic labs are exploring energy-based models that don’t rely on any of these three-but they’re still years away from practical use.
For now, the field is split. Enterprises use next-token prediction for automation because it’s proven, reliable, and well-documented. Researchers use masked modeling for analysis because it extracts meaning better. Creators use denoising for art because it’s the only way to get photorealistic results. But the trend is clear: the best models won’t be built on one objective. They’ll be built on combinations.
Real-World Challenges Developers Face
Practical use isn’t as smooth as the research papers suggest. On GitHub, 43% of issues with diffusion models are about slow inference. Developers waste hours waiting for images to render. Meanwhile, 31% of masked modeling issues relate to fine-tuning instability-models forget what they learned when you tweak them. And for next-token models, 26% of issues are about output coherence degrading over long conversations.
Training costs are another barrier. Masked modeling takes 3-5 weeks on 128 GPUs. Next-token prediction? GPT-3’s training cost was estimated at $4.6 million. Denoising needs even more: 30 days on 64 A100s. Most startups can’t afford this. That’s why smaller, distilled versions are booming. DistilBERT, TinyGPT, and SD-Lite are now common in production.
And then there’s the data problem. Emily Bender from the University of Washington warns that next-token prediction doesn’t understand-it just mimics. If your training data is biased, the model amplifies it. And since denoising models are trained on image-text pairs scraped from the web, they often generate harmful stereotypes. Regulatory bodies like the EU are now requiring full documentation of pretraining data. Non-compliance could mean fines under the AI Act.
Final Thoughts: Choose Based on What You Need
There’s no "best" pretraining objective. Only the right one for your job. Need to extract facts from contracts? Use masked modeling. Build a customer service bot? Go with next-token prediction. Generate product visuals? Denoising is your only real option.
And don’t fall for the hype. Masked modeling won’t replace GPT. Denoising won’t solve all image problems. The future belongs to hybrid systems-but we’re not there yet. For now, understand the trade-offs. Know what each method can and can’t do. Because in generative AI, the pretraining objective isn’t just a technical detail-it’s the foundation of everything the model can become.



Tonya Trottman
6 March, 2026 - 20:31 PM
Masked modeling is way overhyped. BERT’s bidirectional context is neat, sure, but it’s basically just a fancy autocomplete that can’t finish a sentence without throwing a tantrum. Meanwhile, next-token prediction just chugs along like a train on rails-no insight, just momentum. And don’t even get me started on denoising. You call that art? I’ve seen toddlers draw more coherent cats than Stable Diffusion. This whole field feels like we’re teaching neural nets to mimic human thought by throwing spaghetti at the wall and calling it a masterpiece.
Rocky Wyatt
7 March, 2026 - 09:22 AM
Y’all are missing the point. It’s not about which method is ‘better.’ It’s about which one lets you sleep at night. Masked modeling? Great for analysis, terrible for real-world use. Next-token? Makes bots that sound like they’ve been raised on 4chan. Denoising? Turns every dog into a 17th-century painting with extra legs. We’re not building intelligence-we’re building hallucination engines with better UIs. And yet, corporations are betting billions on this. I’m just waiting for the first AI to write a suicide note and blame its training data.
Santhosh Santhosh
7 March, 2026 - 14:57 PM
I have been thinking deeply about this topic for weeks now, and I feel compelled to share my reflections. The pretraining objectives are not merely technical choices-they are philosophical stances on how we understand language, perception, and creativity. Masked modeling treats language as a puzzle to be solved with symmetry and context, which speaks to a deeply human desire for coherence. Next-token prediction, on the other hand, embraces the chaos of emergence-each word a ripple in an endless stream of probability. And denoising? It is almost spiritual: starting from noise, from pure randomness, and patiently, step by step, allowing beauty to emerge. This mirrors meditation, perhaps. Or the slow unraveling of truth. I wonder-do these models dream? Do they feel the weight of the data they ingest? Or are we simply projecting our own longing for meaning onto statistical mirrors?
Veera Mavalwala
8 March, 2026 - 23:25 PM
Oh honey, you think this is deep? Let me paint you a picture. Masked modeling is like your aunt who reads the newspaper backwards because ‘she likes to think differently.’ Next-token prediction? That’s your cousin who memorized every episode of Grey’s Anatomy and now thinks she’s a doctor. And denoising? Sweetheart, that’s the AI version of a TikTok filter-glamour over substance, pixels over truth. I’ve seen AI-generated art where the cat has five tails and the sun is a screaming face. People pay money for this? We’re not advancing intelligence-we’re just making prettier hallucinations. And don’t even get me started on how these models regurgitate every toxic meme from 2012 like it’s sacred scripture.
Ray Htoo
10 March, 2026 - 17:34 PM
I really appreciate how clearly this breaks down the three approaches. One thing I’d add is that hybrid models aren’t just combining techniques-they’re compensating for each other’s blind spots. Masked modeling gives context, next-token gives flow, and denoising gives fidelity. It’s like building a car: you need an engine, wheels, and a frame. You can’t just glue a turbocharger to a bicycle and call it a Tesla. Also, I think the real innovation isn’t in the architecture-it’s in the training data curation. The models are mirrors, but the data is the face they reflect. If we stop scraping the internet like a dumpster diver and start curating with intention, we might actually build something that doesn’t vomit conspiracy theories every time you ask it to explain quantum physics.
Natasha Madison
11 March, 2026 - 19:45 PM
Who funded this? Big Tech. Who benefits? Big Tech. Who gets left behind? Everyone else. These ‘pretraining objectives’ are just Trojan horses for surveillance capitalism. Masked modeling? That’s how they map your thoughts before you even type. Next-token? That’s how they predict your next move-your vote, your purchase, your breakup. Denoising? That’s how they generate fake protests, fake news, fake elections. And now they’re calling it ‘AI.’ This isn’t innovation. It’s social engineering with better graphics. The EU’s AI Act? Too little, too late. They’re already using this to manipulate elections in 17 countries. Wake up. You’re not using AI. AI is using you.
Sheila Alston
13 March, 2026 - 03:49 AM
It’s just so disappointing how we’ve turned something so beautiful-language, creativity, thought-into a corporate product line. We used to write poems. Now we prompt bots. We used to draw with charcoal. Now we type ‘hyperrealistic cat wearing a top hat’ and call it art. And the worst part? We’re proud of it. We post it on Instagram like it’s a personal achievement. But it’s not us. It’s a statistical ghost that ate a library. And we’re the ones applauding. Where’s the humility? Where’s the reverence? This isn’t progress. It’s a slow, shiny, algorithmic suicide of human creativity. And we’re not even crying.
sampa Karjee
14 March, 2026 - 21:16 PM
Let me be blunt: you’re all amateurs. Masked modeling? A toy for undergrads who think bidirectional attention is ‘deep learning.’ Next-token? A glorified Markov chain with a billion parameters and zero understanding. Denoising? A brute-force pixel-pusher that needs a datacenter to generate a cat. Real researchers are working on energy-based models, causal inference architectures, and neurosymbolic hybrids. The papers you’re reading? They’re three years out of date. The field is being run by marketing departments with Jupyter notebooks. And you’re all here arguing about whether BERT is better than GPT like it’s a sports match. Wake up. The real revolution isn’t in the architecture-it’s in the epistemology. But you’re too busy liking AI-generated selfies to care.
Patrick Sieber
16 March, 2026 - 09:52 AM
Really solid breakdown. One thing I’d add is that the compute costs aren’t just technical-they’re ethical. Training a single GPT-3 model used more energy than 120 Irish homes in a year. And we’re still treating this like a tech sprint, not a planetary crisis. We need open-weight models, not closed walled gardens. We need energy-aware training, not just ‘bigger is better.’ And we need to stop pretending that a model that can write a Shakespearean sonnet is somehow ‘intelligent.’ It’s not. It’s a very sophisticated echo chamber. Let’s stop worshiping the machine and start building systems that serve people, not shareholders.
Kieran Danagher
18 March, 2026 - 04:06 AM
Next-token prediction is the only one that actually works. Everything else is just fancy scaffolding.