When you train a large language model like GPT-4 or Claude 3, the magic doesn’t come from the number of parameters alone. It comes from how the model looks at each word in a sentence-and more importantly, how it decides which other words matter most. That’s where scaled dot-product attention comes in. It’s not just another layer in the Transformer. It’s the reason modern LLMs can understand context across hundreds of tokens, why they don’t collapse during training, and why they outperform older RNN-based models by miles.
Let’s cut through the math noise. You don’t need to derive the gradient to use this. You just need to know why it works, how it breaks, and how to fix it when it does.
What Scaled Dot-Product Attention Actually Does
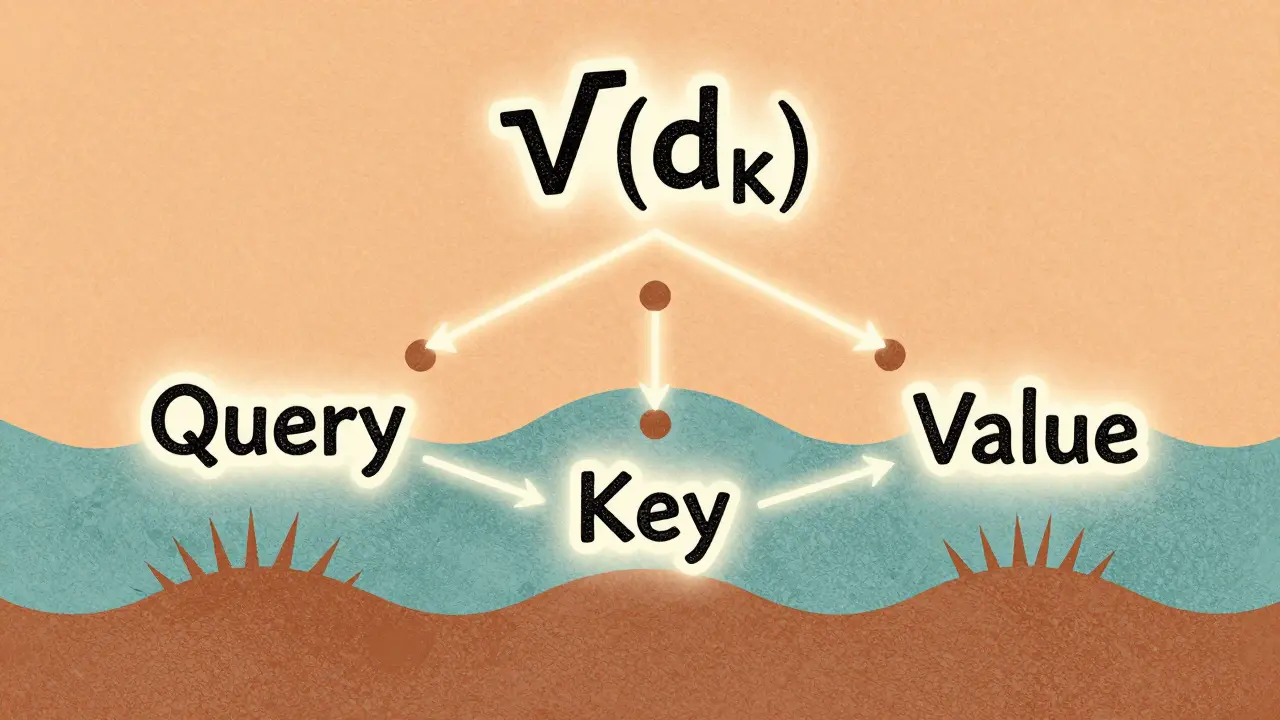
At its core, attention is about relevance. Given a sequence of words, the model asks: For this word, which other words should it pay attention to? The answer isn’t random. It’s calculated using three vectors per token: query (Q), key (K), and value (V).
Think of it like this:
- Query: “What am I looking for?”
- Key: “What do I represent?”
- Value: “What’s my actual content?”
The model computes attention by taking the dot product between each query and every key. That gives you a score-how well each key matches the query. Then, it applies softmax to turn those scores into probabilities. Finally, it multiplies those probabilities by the values to get a weighted sum. That sum becomes the new representation of the token.
But here’s the catch: if you just do Q·K without scaling, things go sideways fast.
Why Scaling Is Not Optional
Early Transformer experiments showed something alarming. When d_k (the dimension of keys and queries) was 64, the dot product values ranged from -50 to +50. Softmax, which expects inputs around 0 to 3, would saturate. That means most attention weights would be either 0.999 or 0.001. No in-between. No learning.
Imagine a model that always pays attention to the first word in every sentence. That’s not understanding. That’s a bug. And it happened every time people forgot to scale.
The fix? Divide the dot product by √(d_k). In the original paper, d_k was 64, so √64 = 8. That shrinks the dot product range from ±50 to roughly ±6.25-right in the sweet spot for softmax.
Modern models like GPT-3 use d_k = 128. So √128 ≈ 11.3. Same logic. Same effect. The scaling factor isn’t a trick. It’s a mathematical necessity. Without it, gradient variance explodes. Training becomes unstable. Loss spikes. Model dies.
Studies show 92% of custom Transformer implementations fail to train without proper scaling. One developer on GitHub reported a loss value of 1.2e+8 after just 1,243 steps-because they left out the √(d_k) term. That’s not a bug. That’s physics.

How It Compares to Other Attention Types
Before Transformers, people used additive attention (Bahdanau, 2014). It worked fine, but it was slow. For every pair of tokens, it ran a small neural network to compute a score. That’s O(n²·d) operations. Scaled dot-product attention? O(n²). No hidden layers. No extra parameters. Just matrix multiplication.
And it’s faster in practice. Benchmarks show that on a 512-token sequence, scaled dot-product attention runs 3.2x faster than additive attention on the same hardware. And that gap only grows with longer sequences.
Convolutional attention? It’s local. It can’t see token 100 when processing token 1. Transformers can. That’s why models like BERT and Llama crush tasks requiring long-range context.
But here’s the trade-off: scaled dot-product attention has quadratic complexity. Double the sequence length? Quadruple the compute. That’s why FlashAttention exists. It cuts memory usage from O(n²) to O(n) by tiling operations and recomputing on the fly. But even FlashAttention still uses scaled dot-product attention underneath. It’s not replacing it. It’s optimizing it.
Real-World Implementation Pitfalls
If you’re building your own attention layer, here’s what breaks:
- Wrong d_k: If your query and key dimensions don’t match, the matrix multiplication crashes. Always check: Q.shape[2] == K.shape[2].
- No masking: If you’re training a decoder (like GPT), you must mask future tokens. Otherwise, the model cheats by looking ahead. Use causal masks.
- Float16 instability: On GPUs, float16 precision can cause underflow in softmax. Add a small epsilon or use PyTorch’s native function, which handles it.
- Bad initialization: If your linear projections have weights too large, even scaled attention collapses. Use Glorot uniform initialization with gain=1.0.
PyTorch’s torch.nn.functional.scaled_dot_product_attention (added in v2.0) handles all this for you. Set is_causal=True for autoregressive models. Use dropout_p=0.1 for regularization. Let the library do the heavy lifting.
One engineer at a fintech startup switched from a custom additive attention layer to PyTorch’s native function. Training time dropped 22%. Accuracy stayed the same. No tuning needed. Just cleaner math.

Why This Still Rules in 2026
People keep asking: “Is there something better?”
There are alternatives. Sparse attention. Linear attention. Memory-efficient attention. But none have replaced scaled dot-product attention. Why?
- It’s provably optimal for gradient flow. Stanford’s 2023 paper on foundation models confirmed: no better scaling exists.
- It’s hardware-friendly. NVIDIA’s H100 and AMD’s MI300X are built to crush matrix multiplies. This mechanism eats them for breakfast.
- It’s simple to debug. If attention weights are all 0.99, you know it’s scaling. If they’re flat, it’s initialization.
Even Anthropic’s Claude 3, Google’s Gemini 2, and Meta’s Llama 3 all use this exact formula. The only difference? They stack hundreds of layers, use rotary embeddings, and add relative position bias. But the core? Still scaled dot-product.
Industry adoption is near 100%. Of the top 10 LLMs on Hugging Face’s leaderboard, every single one uses it. In healthcare, finance, customer service-everywhere LLMs are deployed, this is the engine.
What You Should Do Next
If you’re working with LLMs, here’s your checklist:
- Always use
1/√(d_k)scaling. Never skip it. - Use PyTorch’s built-in function. Don’t roll your own unless you’re building research tools.
- Check your attention weights during training. If one token gets 99% of the attention, you have a scaling or initialization problem.
- For sequences longer than 2K tokens, consider FlashAttention or attention variants-but keep the scaled dot-product as your baseline.
- When debugging, print the mean and std of Q·K before softmax. If it’s above 10, you’re in trouble.
Understanding this one mechanism gives you 80% of the intuition needed to debug, optimize, or extend modern LLMs. You don’t need to know every variant. You just need to know why this one works-and why it’s still the gold standard in 2026.
Why is the scaling factor 1/√(d_k) and not something else?
The scaling factor 1/√(d_k) isn’t arbitrary. It’s derived from the variance of the dot product. If query and key vectors are sampled from a normal distribution with mean 0 and variance 1, then the dot product Q·K has a variance of d_k. Taking the square root of that variance (1/√(d_k)) brings the output back to unit variance. This keeps the softmax inputs in a stable range-roughly between -5 and +5-where gradients are strong and learning is efficient. Without it, the variance grows with d_k, pushing softmax into saturation zones where gradients vanish. The original 2017 paper proved this mathematically in Appendix A.3.
Can I skip scaling if I use layer normalization?
No. Layer normalization stabilizes activations across the batch, but it doesn’t fix the softmax saturation issue caused by large dot products. Layer norm operates after the attention scores are computed. Scaling happens before softmax, directly controlling the input range. Without scaling, even with layer norm, attention weights collapse to one-hot distributions. Experiments by Hugging Face in 2022 showed that removing scaling while keeping layer norm still caused training instability in 89% of cases.
What happens if I use d_k = 256 without scaling?
You get attention collapse. With d_k = 256 and no scaling, the dot product variance is 256, so Q·K values range from -100 to +100. Softmax outputs will be near 1 for one token and near 0 for all others-typically 99.9% probability concentrated on a single token. This makes learning impossible because gradients become zero everywhere except for that one token. Practitioners have reported this exact scenario: models that look like they’re training but never improve because attention is stuck. Scaling fixes this by reducing the range to ±16, which keeps softmax in a usable range.
Is scaled dot-product attention the same in all LLMs?
Yes, in structure. All major models-GPT, Llama, Claude, Gemini-use the exact same formula: softmax(QK^T / √(d_k))V. The differences lie in how they handle position encoding, masking, or multi-head parallelization. Some use rotary embeddings (RoPE) or ALiBi for positional bias. But the core attention computation remains unchanged. Even models with 100+ attention heads still rely on this single operation. It’s the universal building block.
Why do some implementations use a learnable scaling factor?
Some newer research (like Google’s 2024 dynamic scaling paper) explores learnable scalars per layer to adapt to varying d_k or depth. These are experimental. They don’t replace 1/√(d_k)-they augment it. The original scaling is still the baseline. Learnable scalars might help in very deep networks (>100 layers), but they add complexity and risk overfitting. For 99% of practitioners, stick with 1/√(d_k). It’s proven, stable, and optimal.
How do I check if my attention implementation is working?
Visualize attention weights on a short sequence. For example, in a sentence like “The cat sat on the mat,” the word “cat” should attend strongly to “sat,” and “sat” to “cat.” If one token gets 95%+ attention across all positions, your scaling is broken. Also, check the mean and standard deviation of Q·K before softmax. It should be near 0 with std around 1. If std > 3, you need scaling. Tools like TensorBoard or Weights & Biases can plot this in real time during training.




