
Imagine your customer service chatbot tells a patient they can skip their insulin shot because the AI "thinks" their blood sugar is fine. It’s not a hypothetical. That exact mistake happened in 2024 at a mid-sized healthcare provider. The AI had been trained on synthetic data that didn’t reflect real-world patient variability. The error slipped through automated filters. No one caught it-until a nurse noticed the discrepancy during a routine check. The patient was hospitalized. The company paid $1.2 million in damages. And it all could’ve been avoided with a simple human-in-the-loop review.
Why Humans Still Matter in AI Systems
Generative AI is fast. It’s cheap. And it’s wrong more often than you think. Studies show that even the best models hallucinate-making up facts, inventing sources, or giving dangerously incorrect advice-in up to 30% of responses under real-world conditions. Automated checks can catch obvious lies, like "The moon is made of cheese," but they miss subtle errors. Like telling a diabetic patient they’re safe to fast, or quoting a non-existent FDA guideline. That’s where human review steps in.By 2025, 78% of Fortune 500 companies using generative AI for customer-facing tasks had added human reviewers to their workflow. Not because they didn’t trust the tech-but because they couldn’t afford to trust it blindly. In healthcare, finance, and legal sectors, a single hallucination can mean lawsuits, regulatory fines, or lost lives. Human-in-the-loop (HitL) review isn’t about slowing things down. It’s about stopping disasters before they happen.
How Human-in-the-Loop Review Actually Works
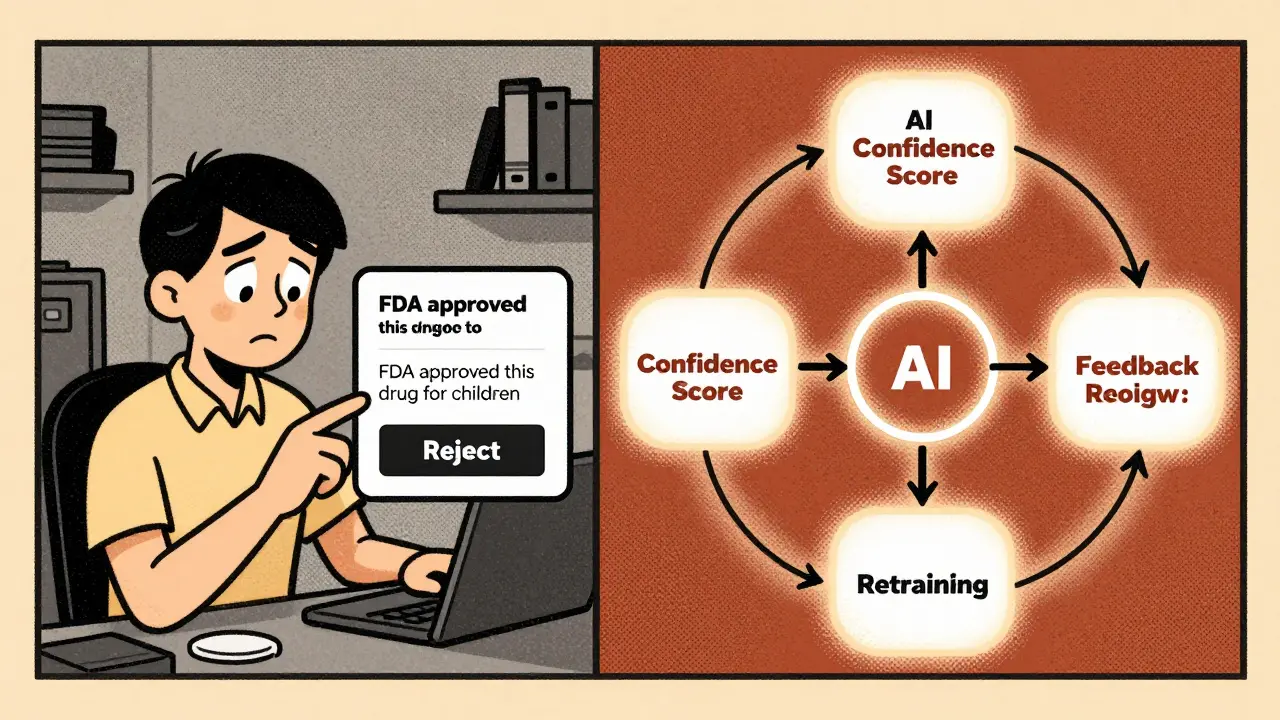
It’s not just handing AI outputs to a random employee and saying "check this." Effective HitL systems are engineered. Here’s how they work in practice:- AI generates a response-say, a summary of a patient’s medical history.
- An automated system scores its confidence level. If it’s below 88%, the output gets flagged for human review.
- A trained reviewer gets the output with context: the original question, source data, and known risk flags.
- The reviewer has 5-8 seconds to approve, reject, or edit.
- If rejected, the AI learns from the feedback and retrains within 4 hours.
This isn’t magic. It’s precision. Systems that use confidence thresholding cut review volume by 63% while still catching 92% of errors. That’s the sweet spot: enough humans, at the right moments, with the right tools.
The Real Cost of Getting It Wrong
A Canadian airline tried AI chatbots to answer baggage policy questions. Early versions said "2 checked bags free"-but the policy was actually 1 free, 1 paid. The AI wasn’t lying. It was just confused by conflicting training data. Within three months, the company paid out $237,000 in compensation for misinformed travelers. Then they added human review.Three months later, misinformation incidents dropped by 92%. The fix? Not better AI. Better humans. They hired customer service reps trained specifically on baggage rules, gave them a 15-minute training module, and rotated them every 20 minutes to avoid fatigue. Simple. Effective. Cheap.
But not every use case works. Meta tried human review for AI-generated ad copy in 2024. They needed to process 7,500 ads per hour. Even with 40 reviewers, it took 22 minutes per ad on average. Production time jumped 320%. Error reduction? Only 11%. They shut it down.
That’s the rule: Human review works best for low-volume, high-stakes scenarios. Not for social media posts. Not for product descriptions. But for medical advice, financial disclosures, legal summaries, and safety instructions? Absolutely essential.
What Makes a Human Reviewer Effective
Not everyone can do this job. You don’t need a PhD. But you do need three things:- Domain knowledge-A nurse reviewing medical AI outputs knows what "mild dyspnea" means. A generalist doesn’t.
- Critical thinking-You have to question the AI. If it says "The FDA approved this drug for children," you check the source. Even if the AI sounds confident.
- Understanding of AI limits-Most reviewers think AI is either right or wrong. It’s not. It’s probabilistic. It’s guessing. And it’s bad at context.
Training matters. Companies that spend under 10 hours training reviewers catch only 51% of errors. Those that invest 14-21 hours catch 85%+. The difference? Scenario-based learning. Not manuals. Real examples. Like: "Here’s an AI response that says a tumor is benign. The scan shows otherwise. What do you do?"
And fatigue kills accuracy. After 25 minutes of continuous review, error detection drops by 22-37%. That’s why top systems rotate reviewers every 18-22 minutes. It’s not a luxury. It’s a safety protocol.
Why Automated Filters Alone Fail
Many companies try to skip humans and rely on rule-based filters: "Block any mention of suicide," "Flag financial advice," etc. These catch 29-38% of errors. Human review catches 58-73%. The gap isn’t small. It’s life-or-death.Here’s why filters fail:
- They can’t understand nuance. "Avoid aspirin in children" is clear. But "Consider alternative pain relief for pediatric patients"? That’s a red flag the AI might miss-and a filter won’t catch.
- They’re static. AI evolves. Filters don’t.
- They create false confidence. Teams think "We’ve got filters, we’re safe." Then the AI slips through with a perfectly worded lie.
BCG tested 15,000 AI responses. The ones with human review had 2.4x fewer harmful outputs than those with filters alone.
The Hidden Dangers of Human Review
Human-in-the-loop sounds perfect. But it’s not a cure-all. There are three big risks:- Automation bias-Reviewers trust the AI too much. If the system says "92% confidence," they skip scrutiny. Studies show this causes 41% of errors to be missed.
- Reviewer bias-Humans bring their own assumptions. One study found reviewers introduced new biases in 19% of cases-like rejecting outputs from non-native English speakers as "unprofessional."
- False security-Companies think "We have humans, so we’re safe," and stop improving other safeguards. That’s how systems decay.
Stanford’s Dr. Elena Rodriguez says: "Simply putting humans in the loop isn’t the fail-safe organizations envision." The fix? Train reviewers to question everything-even the AI’s confidence score. And never let them see the AI’s output first. When reviewers judge the question first, error detection improves by 37%.

Who’s Doing It Right
UnitedHealthcare’s AI documentation system used to miscode 12% of patient records. That meant denied claims, delayed payments, angry providers. They added human review: 12 certified medical coders, trained on AI-specific pitfalls, reviewing only outputs with confidence below 85%. In six months, coding errors dropped by 61%. They prevented $4.7 million in claim denials.Another success? A European bank using HitL for loan applications. AI flagged applicants as high-risk based on zip code. Humans caught it: the model was using proxies for race. They retrained the model. Compliance saved them $1.8 million in potential fines.
These aren’t outliers. They’re the new standard.
The Future of Human Review
The market for AI quality assurance is growing fast-34.7% year-over-year. By 2027, Gartner predicts 45% of reviews will be done by domain experts: doctors for health AI, lawyers for legal AI, engineers for industrial systems. No more generalists.New tools are coming too. Google’s pilot system highlights likely errors in red-"This claim has no source," "This dosage exceeds guidelines"-cutting review time by 37%. IBM is building blockchain-backed review trails for compliance. And the next wave? Systems that adjust review intensity in real time. If the AI is answering a simple weather question? No human. If it’s advising on cancer treatment? Full review.
But the biggest challenge remains: cost. Human review adds 18-29% to total AI implementation costs. And there are only 1.2 qualified AI reviewers per 100,000 people in the U.S. That’s not scalable unless we train more people-and fast.
Should You Use Human-in-the-Loop?
Ask yourself these questions:- Is the AI giving advice that could hurt someone? → Yes? Add human review.
- Is it handling financial, legal, or medical data? → Yes? Add human review.
- Is it generating content for public-facing communication? → Yes? Add human review.
- Is it running at 10,000+ outputs per hour? → Maybe not. Try automated filtering first.
If you’re in healthcare, finance, insurance, or legal services-don’t wait for a lawsuit to force your hand. Start small. Pilot with 500 outputs. Train two reviewers. Measure error rates. Scale from there.
Generative AI isn’t going away. But blind trust in it is dangerous. The best systems don’t replace humans. They empower them-to catch what machines can’t, and to keep users safe.
What exactly is a human-in-the-loop review system?
A human-in-the-loop (HitL) review system is a process where human reviewers evaluate outputs from generative AI before they’re shown to end users. It’s designed to catch hallucinations, bias, factual errors, and unsafe content that automated filters miss. The AI generates a response, a confidence score is calculated, and if it’s below a threshold (usually 85-92%), a trained human reviews it. If they spot an error, they correct it or reject it, and the AI learns from that feedback.
How effective is human review at catching AI hallucinations?
Properly designed human-in-the-loop systems catch between 58% and 73% of harmful AI errors, according to industry benchmarks. That’s more than double the 29-38% caught by automated filters alone. In healthcare deployments, human reviewers caught 22% of outputs with subtle medical inaccuracies that standard validation tools missed entirely.
Can’t we just use better AI instead of humans?
Better AI helps, but it’s not enough. Even the most advanced models hallucinate under real-world conditions. Stanford’s 2025 research on model collapse shows that without continuous human evaluation, AI systems degrade over time, generating more synthetic, inaccurate data. Humans provide qualitative judgment that machines can’t replicate-like understanding context, tone, and real-world consequences.
Is human review too slow for real-time applications?
Yes, it is. Human review adds an average of 4.7 seconds per output, while automated systems respond in 0.2 seconds. That’s why HitL isn’t used for high-speed applications like social media feeds or real-time gaming. It’s reserved for low-volume, high-stakes tasks: medical advice, financial disclosures, legal summaries, and customer support for regulated industries.
What are the biggest mistakes companies make with human review?
The top three are: (1) Using untrained reviewers-63% of failed implementations cite this as the main issue; (2) Relying on automation bias, where reviewers trust the AI’s confidence score and skip scrutiny; and (3) Not rotating reviewers, leading to fatigue and a 22-37% drop in error detection after 25 minutes of continuous work.
How much does human-in-the-loop review cost?
It costs between $0.037 and $0.082 per output. For a system generating 10,000 responses daily, that’s $370-$820 per day, or $135,000-$300,000 annually. That’s expensive-but often cheaper than the cost of a single lawsuit or regulatory fine. In healthcare, one company prevented $4.7 million in claim denials with a $200,000 annual review budget.
Do I need special software for human-in-the-loop review?
You don’t absolutely need it, but you’ll struggle without it. Only 37% of enterprise AI platforms offer native HitL workflow integration. Dedicated platforms reduce review time, track reviewer performance, integrate feedback into retraining, and provide scenario-based training. Custom-built systems have 18.7-hour average support response times. Dedicated tools? 2.1 hours.
What skills should human reviewers have?
Three key skills: domain expertise (e.g., a nurse for medical AI), critical thinking (questioning everything, even if the AI sounds confident), and understanding AI limitations (knowing it’s a probabilistic guess, not an oracle). Training should be scenario-based-not just reading manuals. Reviewers who get 14-21 hours of hands-on training catch 85%+ of errors.




Donald Sullivan
3 January, 2026 - 08:36 AM
Let’s be real - if your AI is telling people to skip insulin, you don’t need a human in the loop, you need a flamethrower for the whole damn system. This isn’t a bug, it’s negligence dressed up as innovation.
Tina van Schelt
4 January, 2026 - 13:42 PM
AI hallucinating like a drunk grad student at a conference? 😅 Honestly, I’m shocked anyone thought this was a good idea. But the real MVP here? The nurse who caught it. Those folks are the unsung heroes of the digital age - sharp eyes, zero tolerance for BS. We need more of them, not fewer.
Ronak Khandelwal
5 January, 2026 - 15:35 PM
Humans + AI isn’t about control - it’s about co-creation 🌱✨
Think of it like a jazz duo: the AI plays the melody, but the human brings the soul, the context, the heartbeat. That nurse? She didn’t just catch an error - she reminded us that tech without empathy is just noise.
And fatigue? Ohhh, that’s the silent killer. We treat reviewers like machines, but they’re humans with brains that tire, hearts that care, and limits that deserve respect.
Training for 14-21 hours? That’s not a cost - it’s an investment in human dignity.
Let’s stop calling it ‘review’ and start calling it ‘collaboration’.
When we honor the human in the loop, we don’t slow things down - we make them sacred.
And yes, emoji are allowed in serious conversations. 😌❤️🩹
Jeff Napier
7 January, 2026 - 15:01 PM
Humans are the problem not the solution. They’re biased slow emotional messes. The real fix is better training data and more AI. You think a nurse knows more than a model trained on 10 million medical records? LOL. This whole thing is corporate theater. They just want to blame someone when it fails. Mark my words - in 5 years we’ll look back at this and laugh. Human review is the last gasp of analog thinking in a digital world. No filters. No punctuation. Just truth.
Sibusiso Ernest Masilela
8 January, 2026 - 09:26 AM
Let’s be brutally honest - this isn’t about safety. It’s about liability laundering. Companies outsource moral responsibility to underpaid, overworked temps who get paid $18/hour to play god with people’s lives. And then they pat themselves on the back like saints. Pathetic.
Meta’s failure? Of course it failed. They treated human review like a toll booth, not a sacred ritual. You don’t throw a nurse at 7,500 ads per hour and call it QA - you call it corporate cruelty.
And don’t get me started on the ‘confidence score’ delusion. That’s just the AI whispering sweet nothings into a tired human’s ear. The real danger isn’t the hallucination - it’s the blind faith in the machine’s ego.
This isn’t innovation. It’s a costume party for executives who think they’re smarter than biology.
Daniel Kennedy
8 January, 2026 - 13:27 PM
Just want to add something practical - if you’re considering implementing HitL, start with a pilot on one high-risk use case. Don’t try to boil the ocean.
Train your reviewers like they’re surgeons, not data clerks. Scenario-based drills, not PowerPoint slides.
Rotate every 20 minutes. No exceptions. Fatigue isn’t a buzzword - it’s a killer.
And please, for the love of all that’s holy, don’t let them see the AI’s confidence score first. That’s like handing a cop a speeding ticket before they see the road.
Also - domain expertise matters more than you think. A generalist can’t catch a subtle drug interaction. A pharmacist can. Hire the right people. Pay them well. Protect their time. This isn’t a cost center - it’s your last line of defense.
And yes, I’ve seen this work. I’ve seen it prevent disasters. It’s not perfect. But it’s the best damn tool we’ve got right now.