Author: Calder Rivenhall

Long-Context Risks in Generative AI: Distortion, Drift, and Lost Salience
Long-context AI models can process massive amounts of text, but they struggle with distortion, drift, and lost salience-especially in the middle of documents. Learn how these risks undermine reliability and what’s being done to fix them.
Read More
Post-Training Quantization for Large Language Models: 8-Bit and 4-Bit Methods Explained
Post-training quantization cuts LLM memory use and speeds up inference by 2-3x without retraining. Learn how 8-bit and 4-bit methods like SmoothQuant, AWQ, and GPTQ make it possible-and what you need to know to use them.
Read More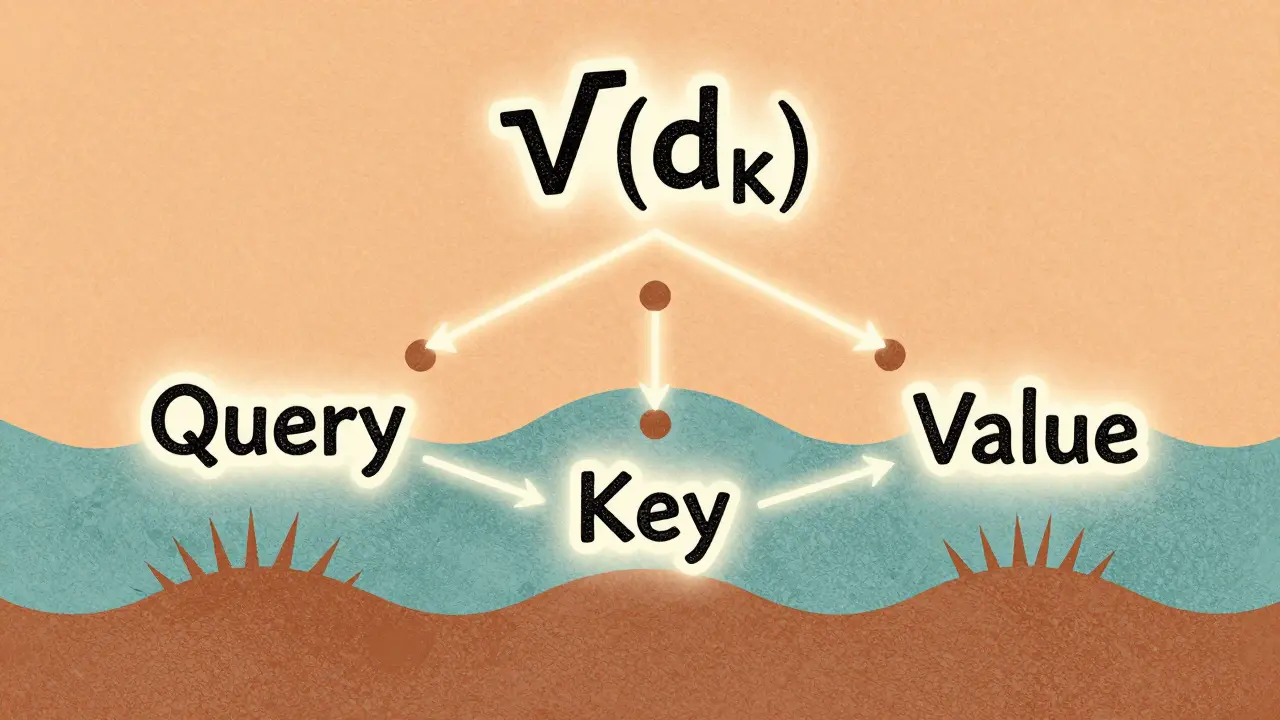
Scaled Dot-Product Attention Explained for Large Language Model Practitioners
Scaled dot-product attention is the core mechanism behind modern LLMs like GPT and Llama. Learn why the 1/√(d_k) scaling is non-negotiable, how it prevents training collapse, and what pitfalls to avoid in practice.
Read More
Ethical AI Agents for Code: How Guardrails Enforce Policy by Default
Ethical AI agents for code are designed to refuse illegal or unethical commands by default, using policy-as-code architecture to enforce compliance without human intervention. This approach is becoming the new standard for trustworthy AI in government, finance, and development.
Read More
Safety by Design in Generative AI: How to Embed Protections into Product Architecture
Safety by Design embeds child protection and harm prevention directly into generative AI architecture-from training data to real-time filtering. This isn't optional. It's the only way to build AI that doesn't become a weapon.
Read More
Transparency and Explainability in Large Language Model Decisions
Transparency and explainability in large language models are critical for trust and fairness. Without knowing how decisions are made, AI risks reinforcing bias and eroding public trust - especially in high-stakes areas like finance and healthcare.
Read More
Data Augmentation for LLM Fine-Tuning: Synthetic and Human-in-the-Loop Approaches
Data augmentation boosts LLM fine-tuning by generating realistic training examples using synthetic methods and human feedback. Learn how synthetic data and human-in-the-loop approaches improve accuracy, reduce costs, and work with LoRA for efficient model adaptation.
Read More
Citations and Sources in Large Language Models: What They Can and Cannot Do
LLMs can generate convincing citations-but most are fake. Learn why AI hallucinates sources, how often they get it wrong, and how to use them safely without trusting their references.
Read More
Pretraining Objectives in Generative AI: Masked Modeling, Next-Token Prediction, and Denoising
Masked modeling, next-token prediction, and denoising are the three core pretraining methods powering today’s generative AI. Each excels in different tasks-from understanding text to generating images. Learn how they work, where they shine, and why hybrid approaches are the future.
Read More
Prompt Compression: How to Reduce Tokens Without Losing LLM Accuracy
Prompt compression cuts LLM token usage by up to 80% without losing accuracy, slashing costs and latency. Learn how techniques like LLMLingua work, where they excel, and how to implement them today.
Read More
Legal Services and Generative AI: Automate Documents, Review Contracts, and Manage Knowledge
Generative AI is transforming legal services by automating document creation, speeding up contract review, and unlocking instant access to legal knowledge. Firms using these tools save hundreds of hours per lawyer annually while improving accuracy and client trust.
Read More
Why Large Language Models Outperform Task-Specific Systems on Many NLP Tasks
Large language models outperform task-specific NLP systems on complex, context-heavy tasks due to their scale, architecture, and ability to generalize. But for simple, domain-specific tasks, traditional models still win on accuracy and efficiency.
Read More