LLM Deployment: How to Run Large Language Models in Production Safely and Affordably
When you deploy a large language model, a powerful AI system trained on massive text datasets to understand and generate human-like language. Also known as LLM, it can answer questions, write code, or summarize documents—but only if you know how to run it without breaking the bank or exposing sensitive data. Most teams fail at LLM deployment because they treat it like a simple API call. It’s not. Running an LLM in production means managing GPU memory, controlling latency, handling spikes in traffic, and staying compliant with privacy laws—all while keeping costs under control.
Successful LLM deployment relies on three key pieces: LLM inference, the process of using a trained model to generate responses in real time, LLM autoscaling, automatically adjusting resources based on demand to avoid overpaying for idle GPUs, and LLM cost optimization, strategies like scheduling, spot instances, and token-level billing to cut cloud expenses by 60% or more. These aren’t optional extras. They’re the foundation. Without autoscaling, you’ll pay for 10 GPUs when you only need 2. Without cost optimization, your AI budget vanishes in a month. Without secure inference, you risk leaking user data or violating regulations like GDPR or California’s AI laws.
What you’ll find here isn’t theory. These posts come from teams that shipped LLMs into real apps—chatbots for customer service, internal knowledge assistants, automated content filters. You’ll see how companies use LLM deployment with Trusted Execution Environments to protect data during inference, how they track usage patterns to predict billing spikes, and how they avoid vendor lock-in by abstracting providers like OpenAI and Anthropic. You’ll learn how to measure success not by how fast the model responds, but by whether it stays reliable, safe, and affordable under real-world load. This collection covers everything from container security and SBOMs to multi-tenancy and export controls. No fluff. No buzzwords. Just what works when your LLM is live, serving users, and costing real money.
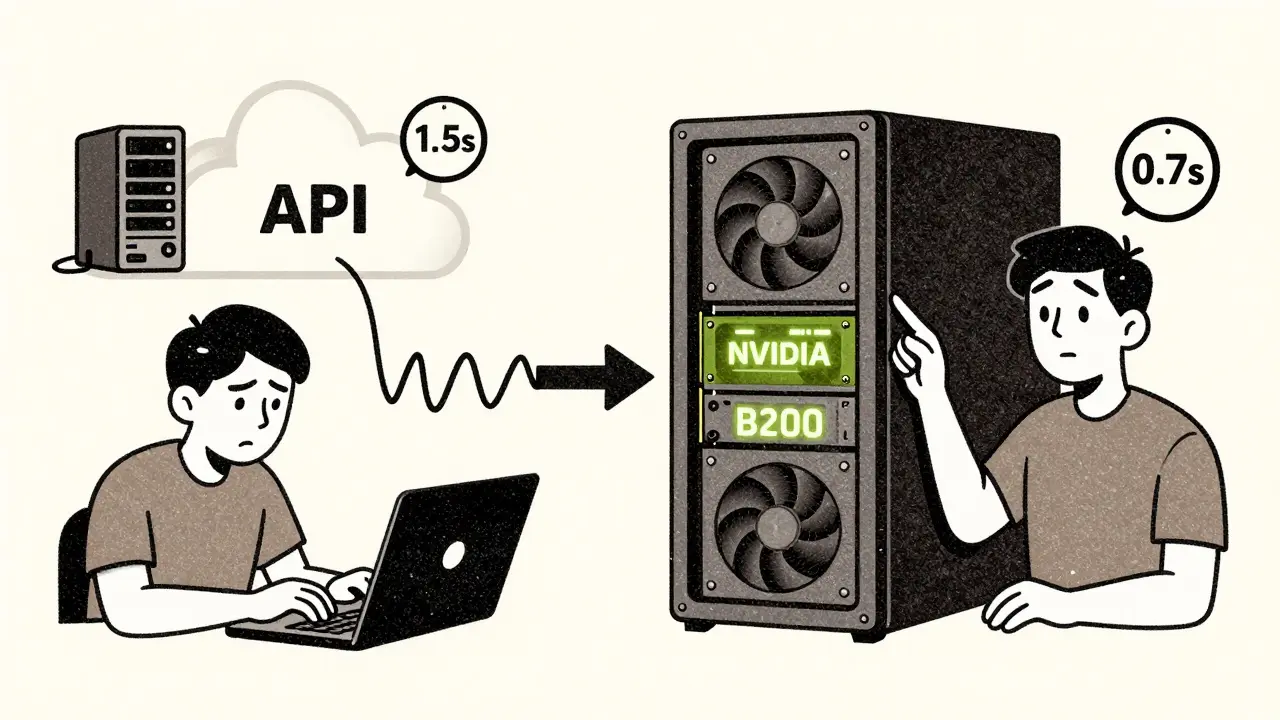
Latency and Control Tradeoffs: API LLMs vs On-Prem Deployment
Choosing between API-based LLMs and on-prem deployment affects latency, data control, cost, and scalability. Learn when to use each-and how top companies combine both for optimal results.
Read More
When to Compress vs When to Switch Models in Large Language Model Systems
Learn when to compress a large language model to save costs and when to switch to a smaller, purpose-built model instead. Real-world trade-offs, benchmarks, and expert advice.
Read More
Hybrid Cloud and On-Prem Strategies for Large Language Model Serving
Learn how to balance cost, security, and performance by combining on-prem infrastructure with public cloud for serving large language models. Real-world strategies for enterprises in 2025.
Read More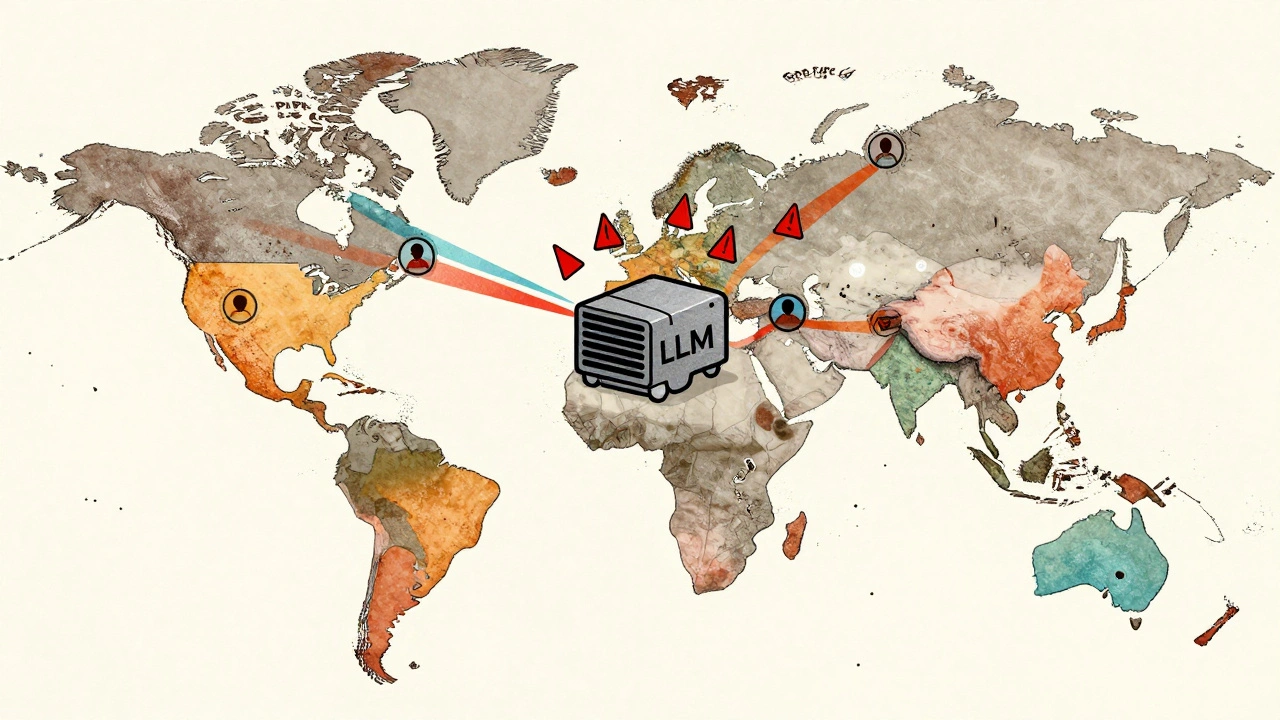
Data Residency Considerations for Global LLM Deployments
Data residency rules for global LLM deployments vary by country and can lead to heavy fines if ignored. Learn how to legally deploy AI models across borders without violating privacy laws like GDPR, PIPL, or LGPD.
Read More
Enterprise Data Governance for Large Language Model Deployments: A Practical Guide
Enterprise data governance for large language models ensures legal compliance, data privacy, and ethical AI use. Learn how to track training data, prevent bias, and use tools like Microsoft Purview and Databricks to govern LLMs effectively.
Read More