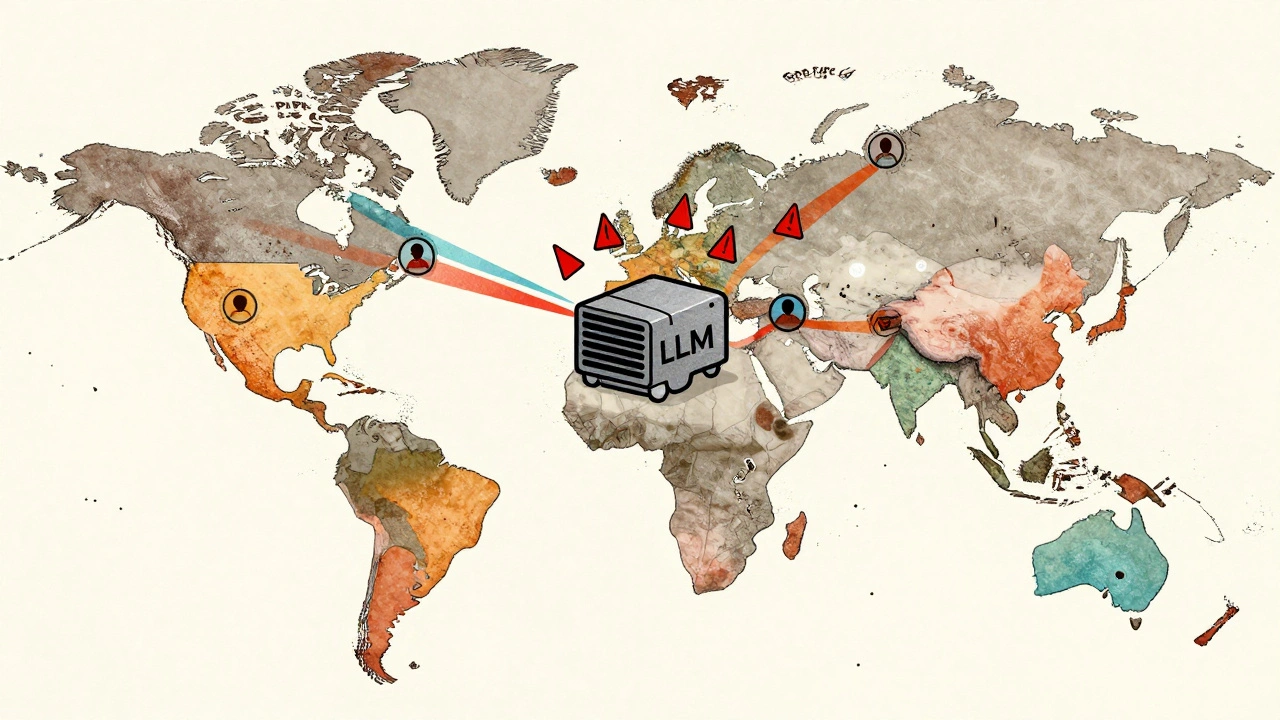
Where your AI stores data matters more than you think
If you're running a large language model (LLM) across borders-whether it's for customer service, content generation, or internal tools-you're not just deploying code. You're moving data. And that data has legal地址, cultural expectations, and real-world consequences tied to it. A model trained in the U.S. but serving users in Germany? That’s not just a technical setup. It’s a legal risk. And if you ignore data residency rules, you could face fines, blocked services, or even criminal liability.
Most companies assume that because their LLM runs on cloud infrastructure like AWS or Azure, they’re covered. That’s not true. The location where user data is processed, stored, or even temporarily cached determines which laws apply. The EU’s GDPR doesn’t care if your server is in Virginia. If a German citizen’s query goes through your system, you’re subject to EU rules. Same goes for Brazil’s LGPD, India’s DPDPA, or China’s PIPL. Each one has different rules about where data can go, how long it can stay, and who can access it.
Why data residency isn’t just about storage
Data residency is often confused with data sovereignty, but they’re not the same. Data sovereignty means a country has legal authority over data generated within its borders. Data residency is about where the data physically resides at any given moment. For LLMs, this gets messy because the model doesn’t just store data-it processes it. Every prompt you type into a chatbot, every document you upload for summarization, every translation request: all of it becomes input data that flows through the system.
Some LLM providers claim they don’t store your data. But even if they don’t keep it long-term, temporary processing in a data center in Singapore or Ireland still counts as residency. And under GDPR, any processing of personal data-even for milliseconds-requires legal justification. If your user is in France and their query hits a server in Texas, you’re transferring data outside the EU. That triggers strict requirements: standard contractual clauses, data protection impact assessments, and sometimes even prior authorization from local regulators.
Companies like Salesforce and Microsoft now offer region-specific LLM endpoints. That’s not a marketing gimmick-it’s a compliance necessity. If you’re serving users in the EU, you need to route their requests to EU-based data centers. Otherwise, you’re violating Article 44 of GDPR, which prohibits international transfers unless safeguards are in place.
Key regions with strict residency rules
Not all countries treat data the same. Here’s what you need to know about the biggest regulatory zones:
- European Union (GDPR): Requires data to stay within the EU/EEA unless specific transfer mechanisms are used. No exceptions for AI training or inference. Even anonymized data can be re-identified, so regulators treat it as personal data.
- United States: No federal data residency law, but state laws like CCPA and CPRA treat location differently. California requires opt-in consent for selling personal data, and if your LLM uses that data for training, you may need to disclose it.
- China (PIPL): Strictly bans cross-border transfer of important data without security review. If your LLM processes data from Chinese users-even if they’re overseas-you may need approval from the CAC (Cyberspace Administration of China). Failure can lead to app removal and fines up to 5% of global revenue.
- India (DPDPA): Requires sensitive personal data to be stored in India. Non-sensitive data can be transferred, but only with consent and after a data protection impact assessment. LLMs that process Aadhaar numbers, health records, or financial details must comply.
- Brazil (LGPD): Similar to GDPR. Requires data localization for sensitive categories. Any breach involving LLM-generated outputs can lead to penalties up to 2% of annual revenue.
- Russia and Saudi Arabia: Require full data localization. All user data must be stored on servers physically located within the country. Cloud providers must have local data centers.
Many organizations assume they can avoid these rules by using U.S.-based models and telling users they’re not storing data. But regulators don’t care about your promises-they care about where the data flows. A 2024 investigation by the European Data Protection Board found that 68% of AI startups using U.S.-hosted LLMs were violating GDPR because they didn’t control data routing.

How to map your LLM deployment to compliance
You can’t just pick a cloud provider and call it done. You need a data residency strategy built into your architecture. Here’s how:
- Map your user locations: Use IP geolocation or user-provided country data to identify where your users are. Don’t assume-track it. If 30% of your users are in Germany, you need EU-compliant infrastructure.
- Choose providers with regional endpoints: Use LLM APIs that let you select data center regions. Anthropic’s Claude, OpenAI’s Azure-hosted models, and Google’s Vertex AI all offer region-specific deployment options.
- Isolate data flows: Create separate instances for different regions. Don’t mix EU user data with U.S. training data. Use virtual private networks or dedicated tenant environments.
- Document everything: Keep logs of where data is processed, who accessed it, and for how long. Regulators will ask for this. If you can’t prove compliance, you’re guilty by default.
- Train your team: Engineers, product managers, and legal teams need to speak the same language. A developer might not realize that enabling logging in Tokyo violates Japan’s Act on the Protection of Personal Information.
One SaaS company serving 50 countries thought they could use a single U.S.-hosted LLM for all users. After a complaint from a French customer, they were fined €4.2 million. The issue? Their system automatically stored prompts for 30 days to improve response quality. That’s a clear GDPR violation.
What happens if you get it wrong
The penalties aren’t theoretical. In 2024, Italy’s data protection authority banned ChatGPT for violating GDPR, citing lack of transparency and unlawful data collection. The model was blocked for six months. Meta was fined €1.2 billion for transferring EU user data to the U.S. using LLM training pipelines. Even if your company is small, you’re not immune.
But fines aren’t the only cost. Your brand reputation takes a hit. Users don’t care if you didn’t mean to break the law. If they find out their personal messages were processed in a country with weak privacy laws, they’ll leave. A 2025 survey by PwC found that 71% of consumers would stop using a service if they learned their data was processed outside their home country.
And then there’s the operational cost. If you’re caught violating data residency laws, you may be forced to shut down services in certain regions. That means losing customers, rewriting code, and rebuilding infrastructure-all while under legal scrutiny.
Practical solutions that actually work
Here’s what successful companies are doing right now:
- Use on-premise LLMs: For highly regulated industries like healthcare or finance, some companies run open-source models like Llama 3 or Mistral on their own servers. That gives them full control over where data lives.
- Deploy hybrid models: Use a local LLM for sensitive tasks (like processing medical records) and a cloud model for general queries. This reduces exposure and keeps high-risk data contained.
- Encrypt everything: Even if data leaves your region, end-to-end encryption can reduce risk. But remember: encryption doesn’t exempt you from residency rules. The data still has to be processed in the right place.
- Use data minimization: Only send what’s necessary. If you’re summarizing a document, don’t send the entire file. Strip out names, addresses, and IDs before sending it to the model.
- Build consent flows: Ask users where they’re from. If they’re in the EU, give them a clear option to opt into EU-only processing. Make it easy to withdraw consent.
One fintech startup in Amsterdam built a custom LLM that only runs on servers in the Netherlands. They trained it on anonymized EU financial data and use it exclusively for Dutch and German customers. Their compliance team spends 15 minutes a week on audits. Their legal team sleeps at night.

What’s coming next
The global landscape is changing fast. In 2025, the U.S. is expected to pass its first federal AI data privacy law, modeled after GDPR. Canada, Japan, and South Korea are tightening their rules too. The AI Act in the EU will classify high-risk LLMs as critical infrastructure-meaning stricter residency and audit requirements.
Don’t wait for a fine to force your hand. Start mapping your data flows now. Talk to your cloud provider about regional endpoints. Audit your prompts. Train your team. Document your choices. The best time to fix data residency issues was yesterday. The second best time is today.
Frequently Asked Questions
Do I need to store all LLM training data in the same country as my users?
No, you don’t need to store training data in the same country as your users. But you must ensure that user input data-what they type into your LLM-is processed and stored in compliance with their local laws. Training data can be sourced globally, but inference (real-time use) must respect residency rules. For example, you can train a model on U.S. data, but if a French user asks a question, their prompt must be handled by a server in the EU.
Can I use a U.S.-based LLM like OpenAI for European customers?
Only if you use OpenAI’s EU-specific endpoint, which routes all data to data centers in Ireland. If you use the default U.S. endpoint, you’re transferring personal data from the EU to the U.S. without adequate safeguards-and that violates GDPR. Many companies have been fined for this. Always check if your provider offers region-specific APIs.
Is anonymizing data enough to avoid residency rules?
No. Under GDPR and similar laws, data is still considered personal if it can be re-identified-even indirectly. If your LLM processes a user’s name, location, or even their writing style, regulators may consider that personal data. Anonymization doesn’t remove the need for compliance. You still need to control where the data flows.
What if my LLM is hosted on my own servers?
You still need to follow data residency rules. Hosting on your own servers doesn’t exempt you-it just means you’re responsible for ensuring those servers are located in the right jurisdictions. If your servers are in the U.S. but serve users in Brazil, you’re still bound by LGPD. Physical control doesn’t override legal jurisdiction.
How do I know which LLM provider is compliant?
Ask for their data residency documentation. Reputable providers like Microsoft Azure, Google Cloud, and Anthropic publish detailed compliance maps showing where their models run. Look for certifications like ISO 27001, SOC 2, and GDPR-specific attestations. If a provider won’t tell you where your data goes, walk away.
Next steps for your team
Start with a simple audit. List every LLM you’re using, where it’s hosted, and which countries your users are from. Then, match each user region to its data protection law. If there’s a mismatch, you have a problem.
Next, talk to your cloud provider. Ask: "Do you offer region-specific endpoints for LLMs?" If they say no, start evaluating alternatives. Don’t wait for a regulator to find you.
Finally, build a policy. Make it clear: no LLM deployment goes live without a data residency review. Assign ownership. Train your engineers. Document every decision. This isn’t optional anymore. It’s the price of doing business with AI in 2025.




Emmanuel Sadi
9 December, 2025 - 15:21 PM
Oh wow, another 'GDPR will save us' lecture. You really think a Nigerian startup with a $200/month AWS bill needs to hire a legal team just because someone in Berlin typed 'hello' into a chatbot? LOL. The real problem is companies using AI to automate customer service while ignoring that most users don't care about data residency - they care if the bot answers their question. Stop over-engineering compliance and start building products.
Nicholas Carpenter
10 December, 2025 - 12:27 PM
This is actually one of the clearest breakdowns I've seen on LLM data residency. I work in health tech and we just switched to Azure's EU region after nearly getting fined. The part about temporary caching being a violation? Eye-opening. I used to think 'we don't store data' was enough - turns out, regulators see it differently. Thanks for the practical checklist.
Chuck Doland
12 December, 2025 - 01:49 AM
The conflation of data sovereignty and data residency remains a persistent conceptual error in industry discourse. Data sovereignty implies jurisdictional authority over data, whereas data residency denotes physical location of processing infrastructure. The legal implications diverge significantly: sovereignty invokes state power, while residency triggers contractual and regulatory obligations under extraterritorial frameworks such as GDPR Article 44. One cannot mitigate risk by assuming technological neutrality; legal jurisdiction is activated by the mere act of data ingress into a regulated territory, regardless of intent or duration.
Madeline VanHorn
12 December, 2025 - 08:06 AM
Ugh. Another tech bro pretending he's a lawyer. If you're using LLMs and don't know where your data goes, you shouldn't be in business. It's not rocket science. Stop pretending compliance is optional because you're 'disrupting' something. You're just a liability waiting to happen.
Glenn Celaya
12 December, 2025 - 19:26 PM
I dont even know why people care anymore. Like who gives a f*** if my chatbot processes data in Texas? If you're in the EU and you're mad about it go cry to your government. They're the ones making all these rules. And btw OpenAI says they dont store data so chill. Its all just fearmongering to sell more cloud services
Wilda Mcgee
12 December, 2025 - 19:30 PM
I love how this post doesn't just throw fear at you - it gives actual tools. The hybrid model idea? Genius. We're using Mistral on our own server for patient notes and GPT-4 for general FAQs. Keeps the sensitive stuff locked down and the rest fast. Also, the consent flow tip? We added a pop-up: 'Where are you from?' and now our EU users feel seen. It's not just compliance - it's trust-building. 💪🌍
Chris Atkins
13 December, 2025 - 17:49 PM
Been running our LLM on a server in Virginia for a year and no one's come knocking. Guess what? Most of our users are in the US anyway. If you're serving global markets you gotta adapt but don't panic. Just know your user base and pick your battles. Cloud providers are way ahead of most of us on this. Just ask them where your data lands. Simple.
Jen Becker
14 December, 2025 - 09:35 AM
I just know one thing. They're watching us. Every word. Every query. Every 'hi'. And now they're gonna charge us for it. This isn't about privacy. It's about control. And they don't want us to win.
Ryan Toporowski
15 December, 2025 - 11:54 AM
Big props to the author 🙌 This is the kind of guide I wish I had 6 months ago. We got slapped with a warning from our legal team after using a US-hosted model for EU users. We switched to Azure EU and now our devs actually understand why region selection matters. Pro tip: make your engineers take a 10-min GDPR quiz. It changes everything. 😊
Samuel Bennett
16 December, 2025 - 11:37 AM
GDPR is a scam. They say 'anonymized data' is still personal but they never explain how. If I strip out names IPs and emails how is that personal? Its just text. Also OpenAI says they delete prompts so why are people getting fined? This is all just corporate fear porn to sell compliance software. And dont even get me started on China's PIPL - they want us to hand over our code too? No thanks.