Imagine training a super-smart AI model that can predict the next word in your sentence or generate realistic medical images, but without ever seeing the raw data from millions of users. That is the promise of Federated Learning, which enables collaborative machine learning where models are trained across distributed devices without centralizing sensitive data. For years, the industry standard was to hoard data in massive central servers. This approach worked until privacy regulations tightened and security breaches became headline news. Now, with the rise of Generative AI, which requires vast amounts of diverse data to create unique outputs, the need for a safer way to collaborate has never been greater.
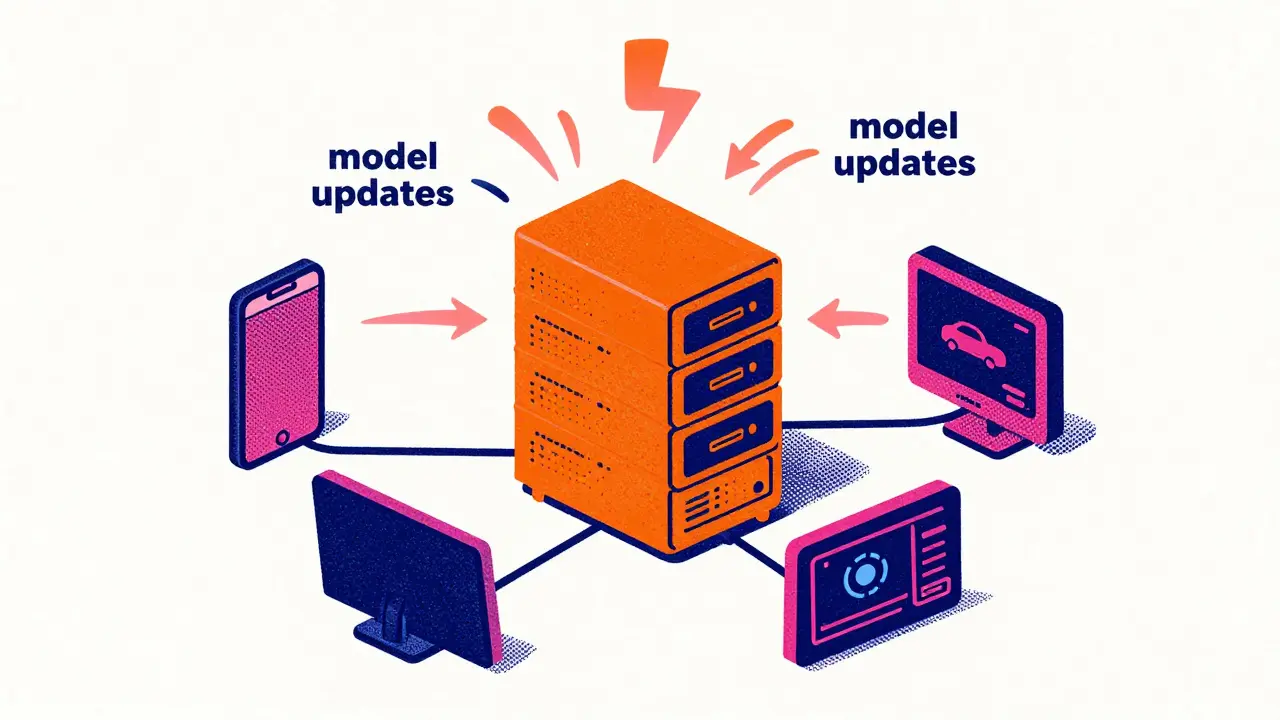
You might be wondering how this actually works. Instead of sending your personal photos, health records, or typing habits to a cloud server, the AI model comes to you. It learns from your local data on your device, sends only the mathematical lessons it learned back to the central server, and then gets updated again. Your raw data never leaves your phone or hospital server. This shift isn't just a technical tweak; it's a fundamental change in how we build intelligent systems in a world that demands privacy.
How Federated Learning Works Under the Hood
To understand why this matters, you need to look at the lifecycle of a federated system. In traditional machine learning, you collect all data into one place. In federated learning, the process is decentralized. Here is the step-by-step flow:
- Local Training: Each participant-whether it’s your smartphone, a self-driving car, or a hospital database-trains a copy of the global model using its own private data.
- Parameter Updates: The device calculates the changes needed to improve the model (these are called gradients or parameter updates). Crucially, this update contains no raw data, just the "lessons" learned.
- Aggregation: These updates are sent to a central server. The server doesn't see your data; it sees thousands of small improvements from different sources.
- Global Update: The server combines these updates into a new, smarter global model version.
- Distribution: The improved model is sent back to all participants, who repeat the cycle.
This architecture solves a major problem: data sovereignty. For example, an automotive company might have vehicles in Germany, Japan, and the US. Data laws in each country prevent them from sharing driving logs across borders. With federated learning, they can jointly train a better autonomous driving model without violating any local regulations because the raw data stays within each country's borders.
Why Generative AI Needs Privacy-Preserving Collaboration
Generative AI models, such as large language models or image generators, thrive on diversity. The more varied the data, the more creative and accurate the output. However, high-quality, diverse data is often locked behind strict privacy walls.
Hospitals want to build AI that can detect rare diseases from X-rays, but they cannot share patient images due to HIPAA or GDPR compliance. Banks want to collaborate on fraud detection algorithms but cannot share customer transaction histories. Federated learning bridges this gap. By allowing these institutions to contribute to a shared model without exposing their proprietary or sensitive datasets, they create a collective intelligence that is far stronger than any single organization could build alone.
Moreover, generative AI can use federated frameworks to create synthetic data. This synthetic data mimics the statistical properties of real data but contains no actual personal information. Organizations can then use this safe, synthetic data to further refine their models, enhancing privacy while maintaining utility.
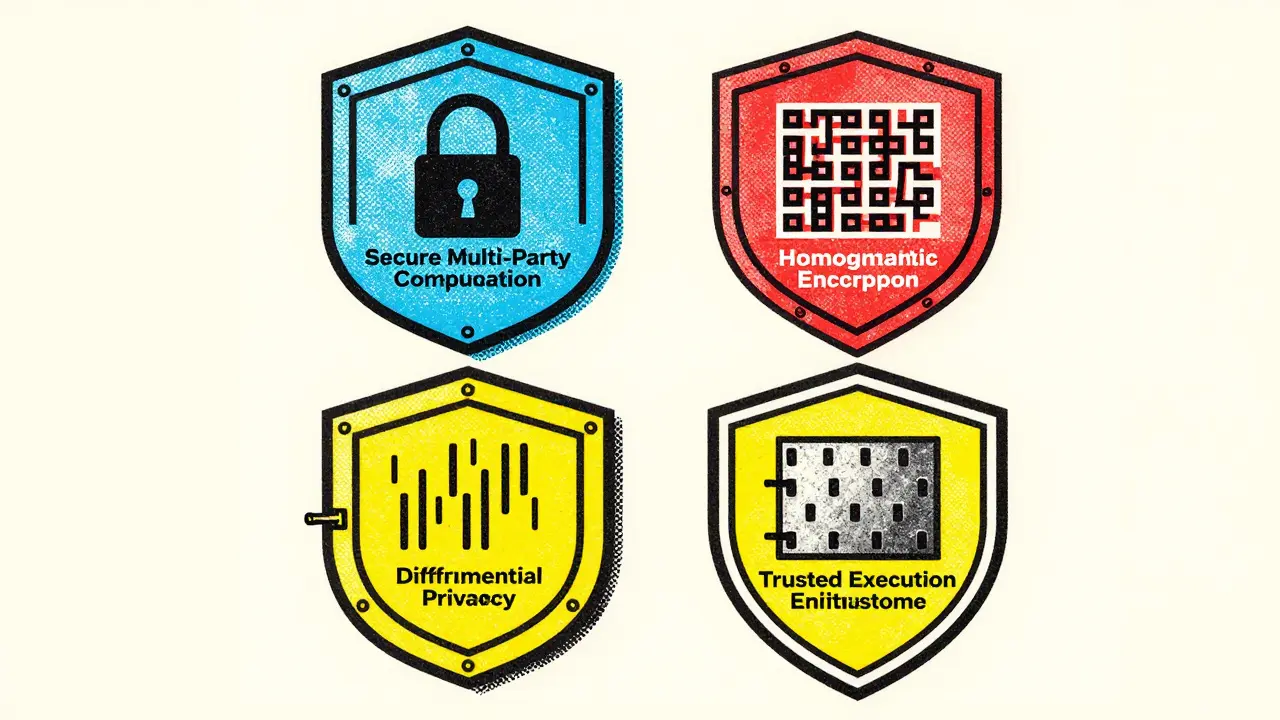
The Four Pillars of Privacy in Federated Systems
Sending model updates instead of raw data is a good start, but it’s not enough on its own. Clever hackers can sometimes reverse-engineer sensitive information from those updates. To prevent this, federated learning employs a layered defense strategy using four key technologies.
| Technique | How It Works | Primary Benefit |
|---|---|---|
| Secure Multi-Party Computation (SMPC) | Allows multiple parties to jointly compute results without revealing individual inputs to each other. | No participant can view another's data during aggregation. |
| Homomorphic Encryption (HE) | Enables computations to be performed directly on encrypted data without decrypting it first. | Data remains unreadable even to the central server processing it. |
| Differential Privacy (DP) | Introduces small amounts of statistical noise to model updates before they are shared. | Makes it mathematically difficult to trace updates back to specific users. |
| Trusted Execution Environments (TEEs) | Uses hardware-level isolation to protect sensitive computations within secure enclaves. | Prevents tampering or unauthorized access at the processor level. |
Think of these techniques as a vault. SMPC ensures no one else has the key, HE keeps the contents scrambled while being moved, DP adds static so eavesdroppers hear nothing clear, and TEEs build the vault out of unbreakable steel. Together, they form a robust shield against data leakage.
Real-World Applications Beyond Theory
This isn't just academic research. Major tech companies are already deploying this at scale. Google’s implementation of federated learning for Android keyboard suggestions is perhaps the most famous example. Millions of smartphones learn from your typing patterns locally, send updates to Google, and collectively improve the prediction engine for everyone-all without Google ever reading your texts.
In healthcare, researchers are using federated learning to train diagnostic models across multiple hospitals. A study involving cancer detection showed that models trained via federation achieved accuracy comparable to centralized training, while keeping patient data secure within each institution. Similarly, financial institutions are collaborating to detect money laundering patterns. By sharing model insights rather than customer ledgers, banks can identify complex fraud rings that span across different banking networks.
The automotive industry also benefits significantly. Self-driving cars generate terabytes of data daily. Sharing this raw video feed is bandwidth-intensive and legally fraught. Federated learning allows car manufacturers to improve navigation and safety algorithms by aggregating driving experiences from vehicles worldwide, respecting local data residency laws.

Challenges and Security Risks You Must Know
Despite its advantages, federated learning is not a magic bullet. It introduces new complexities and attack surfaces that organizations must manage carefully.
First, there is the issue of non-IID data. In statistics, IID stands for "independent and identically distributed." In the real world, data is rarely identical. One user’s typing style is very different from another’s. If the data across devices is too skewed, the global model may struggle to converge or perform poorly for certain groups. Engineers must implement specialized algorithms to handle this heterogeneity.
Second, communication overhead can be significant. Sending model updates over cellular networks consumes battery and data. While smaller than sending raw video, frequent updates still add up. Optimizing when and how often devices participate is crucial for scalability.
Third, and most critically, security threats have evolved. Adversaries can launch "gradient inversion attacks," attempting to reconstruct private images or text from the shared model updates. They can also perform "model poisoning," where a malicious participant injects bad data to corrupt the global model. Defending against these requires continuous monitoring, anomaly detection, and rigorous validation of every update received by the central server.
Is Federated Learning Right for Your Organization?
Deciding whether to adopt federated learning depends on your specific needs. If you operate in a highly regulated industry like finance or healthcare, or if you handle sensitive consumer data, the privacy benefits often outweigh the technical complexity. However, if your data is already public or non-sensitive, traditional centralized training might be simpler and faster.
Consider these factors before diving in:
- Data Sensitivity: Does your data contain PII (Personally Identifiable Information) or trade secrets?
- Regulatory Constraints: Are you bound by GDPR, HIPAA, or other data sovereignty laws?
- Infrastructure Capability: Do you have the engineering resources to manage distributed training pipelines?
- Collaboration Needs: Do you need to partner with competitors or external entities to improve your AI?
If you answered yes to the first three, federated learning is likely a strategic advantage. It allows you to innovate aggressively while maintaining trust with your users and regulators.
What is the difference between federated learning and edge computing?
Edge computing refers to processing data near the source (like a sensor or device) to reduce latency. Federated learning is a specific type of machine learning algorithm that runs on edge devices. While they often work together, edge computing is about infrastructure location, whereas federated learning is about the method of collaborative model training without data sharing.
Can federated learning guarantee 100% privacy?
No technology guarantees 100% absolute security. However, when combined with techniques like differential privacy and homomorphic encryption, federated learning provides a mathematically strong layer of protection. It significantly reduces the risk of data breaches compared to centralized storage, but it still requires robust implementation to defend against sophisticated inference attacks.
How does Google use federated learning?
Google uses federated learning primarily for features like Gboard keyboard predictions and Smart Reply suggestions. The AI model trains on your typing habits locally on your phone. Only the anonymized model updates are sent to Google servers to improve the global model, ensuring your personal messages are never uploaded to the cloud.
What are the main challenges of implementing federated learning?
Key challenges include handling non-IID (non-uniform) data distributions, managing high communication costs over unstable networks, dealing with hardware heterogeneity across devices, and defending against security threats like model poisoning and gradient inversion attacks.
Is federated learning suitable for small businesses?
It depends on the scale. Small businesses with limited data may not benefit immediately. However, if a small business needs to collaborate with larger partners while protecting its proprietary data, federated learning offers a viable path. Cloud-based federated platforms are emerging to lower the entry barrier for smaller organizations.




