Imagine trying to read a novel where you could only look at one word at a time, forgetting everything before it as soon as you moved to the next. That was the reality for early artificial intelligence models. They processed text sequentially, like a person reading line by line without the ability to glance back or ahead. This limitation made them slow and prone to losing context over long passages.
Then came the Transformer, an architecture that changed how machines understand language forever. Introduced in the 2017 paper 'Attention is All You Need' by researchers at Google Brain, this design allowed computers to process entire sentences simultaneously. Today, every major Large Language Model (LLM), from GPT-4 to Llama 3, runs on this foundation. If you want to understand modern AI, you need to understand why the Transformer won out against older technologies.
The Problem with Sequential Processing
Before 2017, Recurrent Neural Networks (RNNs) and their improved cousin, Long Short-Term Memory networks (LSTMs), were the standard for handling sequential data like text. These models worked by passing information from one step to the next. While effective for short sequences, they struggled with what experts call the "vanishing gradient problem." Essentially, as the distance between two words in a sentence increased, the model’s ability to connect them faded away.
Consider the sentence: "The cat, which had been running through the park all day, finally stopped." An LSTM might struggle to link "stopped" back to "cat" because of the intervening clauses. More critically, training these models was incredibly slow. Because each word depended on the previous one, the computer couldn't process multiple words at once. Google’s original experiments showed that training an LSTM-based translation model took weeks, while the new Transformer architecture completed the task in just 3.5 days using eight P100 GPUs. This speed difference wasn't just convenient; it was revolutionary. It meant researchers could train on vastly larger datasets, leading to smarter models.
Self-Attention: The Heart of the Transformer
The secret sauce behind the Transformer's success is Self-Attention. Unlike RNNs, which read left-to-right, self-attention allows the model to look at every word in a sentence at the same time. It calculates the relevance of each word to every other word, creating a web of relationships.
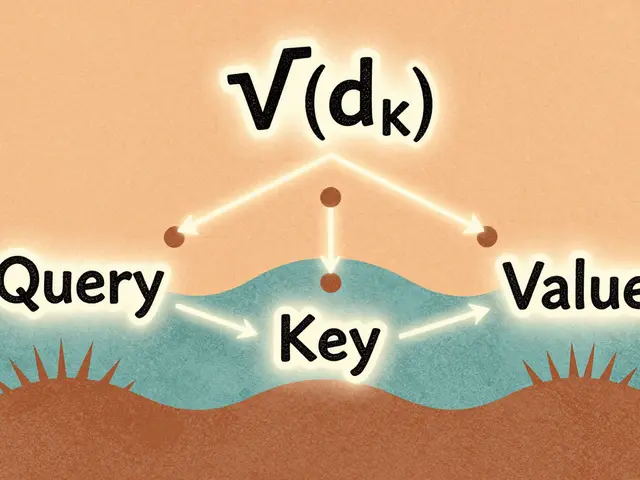
Here is how it works in simple terms. When the model processes a sentence, it converts each word into three vectors: Query, Key, and Value. Think of the Query as what the current word is looking for, the Key as what the word offers, and the Value as the actual content of the word. The model compares the Query of one word with the Keys of all other words. If there is a strong match, it pays more attention to that word's Value.
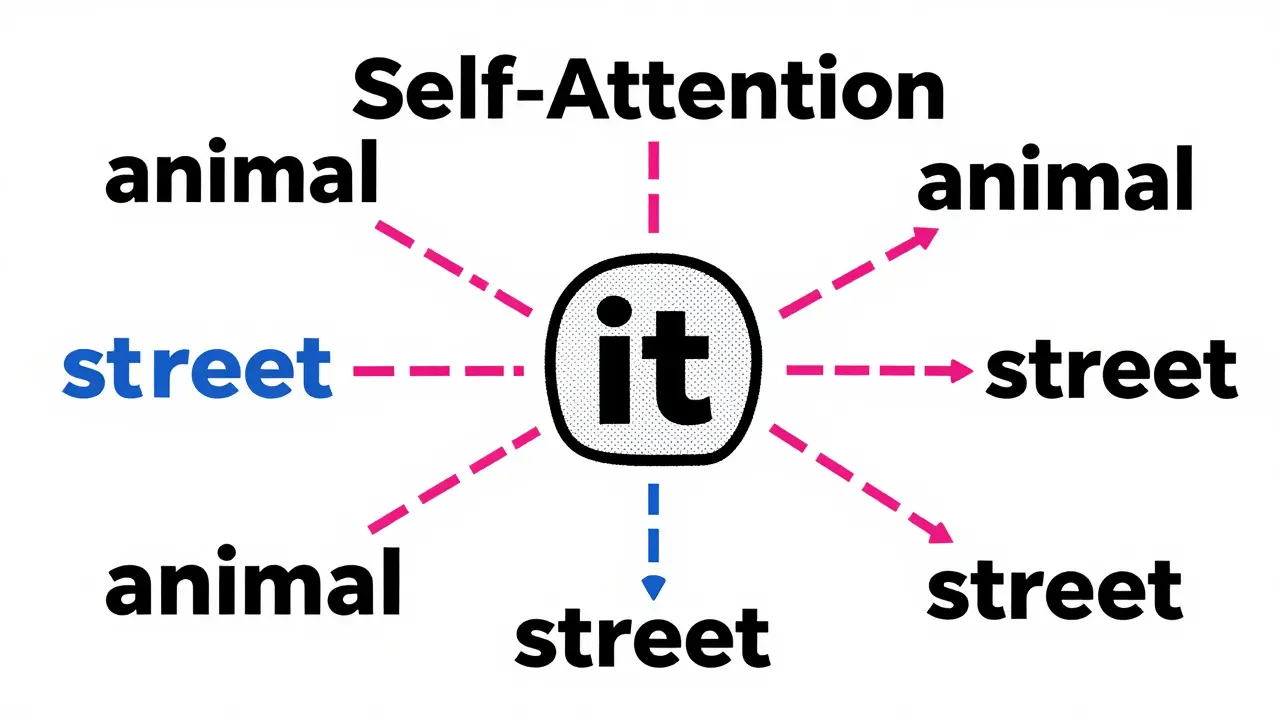
For example, in the phrase "The animal didn't cross the street because it was too tired," the word "it" needs to know if it refers to "animal" or "street." Self-attention calculates scores showing that "it" has a high correlation with "animal" due to semantic similarity, effectively resolving the ambiguity. This mechanism enables the model to capture long-range dependencies that previously confused AI systems. Dr. Demis Hassabis, CEO of DeepMind, noted in a 2022 NeurIPS keynote that this attention mechanism represents one of the most significant architectural breakthroughs in deep learning history.
Encoder-Decoder Structure and Multi-Head Attention
The original Transformer architecture consists of two main parts: the Encoder and the Decoder. The Encoder processes the input text, understanding its structure and meaning. The Decoder generates the output, such as a translated sentence or a continuation of a story. In many modern Large Language Models like GPT-3 or GPT-4, only the Decoder stack is used, as they are designed primarily for generation tasks rather than translation pairs.
Within these layers lies another critical component: Multi-Head Attention. Instead of performing a single attention calculation, the model splits the words into multiple "heads"-typically eight or twelve-and performs attention in parallel. Each head learns different types of relationships. One head might focus on grammatical structure, while another focuses on semantic meaning or entity recognition. These results are then combined. This approach is similar to having several experts analyze a document simultaneously, each bringing a different perspective, before pooling their insights for a final decision.
To ensure the model understands the order of words (since it processes them all at once), developers inject positional encodings. These are mathematical signals added to the word embeddings that indicate position. Without them, the model would treat "dog bites man" and "man bites dog" as identical sets of words. By combining self-attention with positional encoding, the Transformer maintains both global context and precise sequence order.
Why Transformers Beat Older Architectures
The advantages of Transformers over RNNs and LSTMs are clear when looking at performance metrics. In machine translation benchmarks like WMT 2014, the original Transformer achieved a BLEU score of 28.4 for English-to-German translation. This surpassed the previous best ensemble LSTM system by 2.0 points. More importantly, it did so with significantly less computational overhead during inference.
| Feature | RNN / LSTM | Transformer |
|---|---|---|
| Processing Style | Sequential (one token at a time) | Parallel (all tokens at once) |
| Context Window | Limited (vanishing gradients) | Long-range dependencies handled well |
| Training Speed | Slow (weeks for large datasets) | Fast (days for large datasets) |
| Scalability | Poor scaling with data size | Excellent scaling (Chinchilla laws) |
| Memory Complexity | Linear O(n) | Quadratic O(n²) for attention |
This scalability is key. As companies gathered more data, Transformers proved capable of absorbing it efficiently. According to Gartner's 2025 AI Market Guide, 98.7% of new enterprise LLM deployments use Transformer-based architectures. This dominance isn't accidental; it's the result of an architecture that scales linearly with compute power, allowing models to grow from millions to hundreds of billions of parameters while maintaining coherence.

Limitations and Computational Costs
Despite their success, Transformers are not perfect. The biggest drawback is the quadratic complexity of self-attention. If you double the length of the input sequence, the computation required quadruples. For a sequence of 1,024 tokens, the model must calculate approximately 1 million attention scores. This becomes problematic for very long documents, such as legal contracts or entire books.
This limitation has led to innovations like Sliding Window Attention, used in Meta's Llama 3, which processes local contexts efficiently while maintaining global understanding for sequences up to 1 million tokens. Another challenge is the massive hardware requirement. Training a 13-billion parameter Transformer model can cost around $18,500 using high-end AWS instances, according to a 2024 Lambda Labs analysis. This puts advanced experimentation out of reach for individual researchers and small startups.
Furthermore, critics argue that the sheer scale of these models creates an illusion of understanding. Dr. Emily Bender warned in her 2021 paper 'Stochastic Parrots' that these systems mimic language patterns without true comprehension. While they generate fluent text, they may lack factual grounding or logical consistency, leading to hallucinations where the model confidently states incorrect information.
The Future: Hybrids and Efficiency
The industry is actively working to solve these efficiency issues. We are seeing a shift toward hybrid architectures. DeepMind proposed 'Transformer-RNN Fusion Models' in May 2025, aiming to combine the parallelism of Transformers with the sequential efficiency of RNNs. Additionally, State Space Models (SSMs) like the Mamba architecture have emerged as competitors. Released in late 2024, Mamba demonstrated five times faster inference on long sequences compared to comparable Transformers, though it currently lags in accuracy for complex language tasks.
Google's Gemini 2.0, released in 2025, introduced 'Mixture-of-Depths' attention, reducing computational complexity for long sequences by 40%. These developments suggest that while the core concepts of the Transformer will persist, the implementation will evolve. Forrester's 2025 AI Architecture Report predicts that Transformers will remain foundational through 2030, likely evolving into hybrid systems that address current computational bottlenecks.
For developers and businesses, understanding these core concepts is crucial. Whether you are fine-tuning a model for customer support or building a new application, knowing how self-attention works helps you optimize prompts, manage context windows, and anticipate limitations. The era of black-box AI is ending; the future belongs to those who understand the machinery underneath.
What is the main difference between Transformers and RNNs?
The main difference is processing style. RNNs process data sequentially, one token at a time, which makes them slow and prone to losing context over long distances. Transformers process entire sequences simultaneously using self-attention, allowing for parallel computation and better handling of long-range dependencies.
How does self-attention work in simple terms?
Self-attention allows the model to weigh the importance of each word in relation to every other word in the sequence. It uses Query, Key, and Value vectors to calculate relevance scores. This helps the model understand context, such as determining what a pronoun like "it" refers to in a sentence.
Why are Transformers so computationally expensive?
Transformers suffer from quadratic complexity regarding sequence length. As the number of tokens increases, the number of attention calculations grows exponentially. Additionally, training large models requires massive amounts of GPU memory and energy, often costing tens of thousands of dollars.
What is Multi-Head Attention?
Multi-Head Attention splits the input into multiple "heads," each performing self-attention independently. This allows the model to focus on different types of relationships, such as grammar, semantics, or entity links, simultaneously. The results are then combined to form a richer representation of the input.
Are Transformers still the best architecture for LLMs in 2026?
Yes, as of 2026, Transformers remain the dominant architecture for Large Language Models, powering nearly all major commercial AI systems. However, hybrid models and alternatives like State Space Models (e.g., Mamba) are emerging to address efficiency issues, particularly for long-context applications.
What is the vanishing gradient problem?
The vanishing gradient problem occurs in recurrent neural networks when the signal (gradient) used to update weights becomes extremely small as it propagates backward through many time steps. This prevents the network from learning long-term dependencies. Transformers avoid this issue by processing all tokens in parallel and using direct connections via attention mechanisms.