Attention Mechanism in AI: How LLMs Focus on What Matters
Attention mechanism, a core technique that lets AI models weigh the importance of different parts of input data. Also known as self-attention, it’s what lets models like GPT and Llama understand context—not just by reading words in order, but by figuring out which ones actually matter for the answer. Before attention, AI struggled with long texts. It would forget the beginning by the time it reached the end. Now, it can spot that the word ‘bank’ in a sentence about fishing means something totally different than in a sentence about money—all because it learned to pay attention to the right clues.
This isn’t just theory. The attention mechanism is the engine behind transformers, the architecture that powers nearly every major LLM today. Without it, you wouldn’t get reliable retrieval-augmented generation (RAG), a method that pulls in your own data to make LLM answers more accurate. RAG works because the model uses attention to pick out the most relevant chunks from your database, not just guess from memory. It’s why your chatbot can answer questions about your internal docs without needing a full retrain.
And it’s not just about reading. Attention also shapes how models are trained and deployed. In LLM inference, the process of running a trained model to generate responses, attention patterns help predict which parts of the input will slow things down—like long documents or complex questions. That’s why tools like LiteLLM and autoscaling systems track attention queues to keep costs low and speed high. Companies that ignore attention in their infrastructure end up paying for wasted GPU time.
You’ll find posts here that dig into how attention powers real systems: from how it reduces hallucinations in RAG pipelines, to why transformer-based models outperform older ones in enterprise data tasks, to how inference engines optimize attention to cut cloud bills. These aren’t academic papers—they’re guides from developers who’ve built and broken these systems. Whether you’re tweaking prompts, securing model weights, or scaling LLM services, understanding attention isn’t optional anymore. It’s the thing that turns generic AI into something that actually works for your use case.

Long-Context Risks in Generative AI: Distortion, Drift, and Lost Salience
Long-context AI models can process massive amounts of text, but they struggle with distortion, drift, and lost salience-especially in the middle of documents. Learn how these risks undermine reliability and what’s being done to fix them.
Read More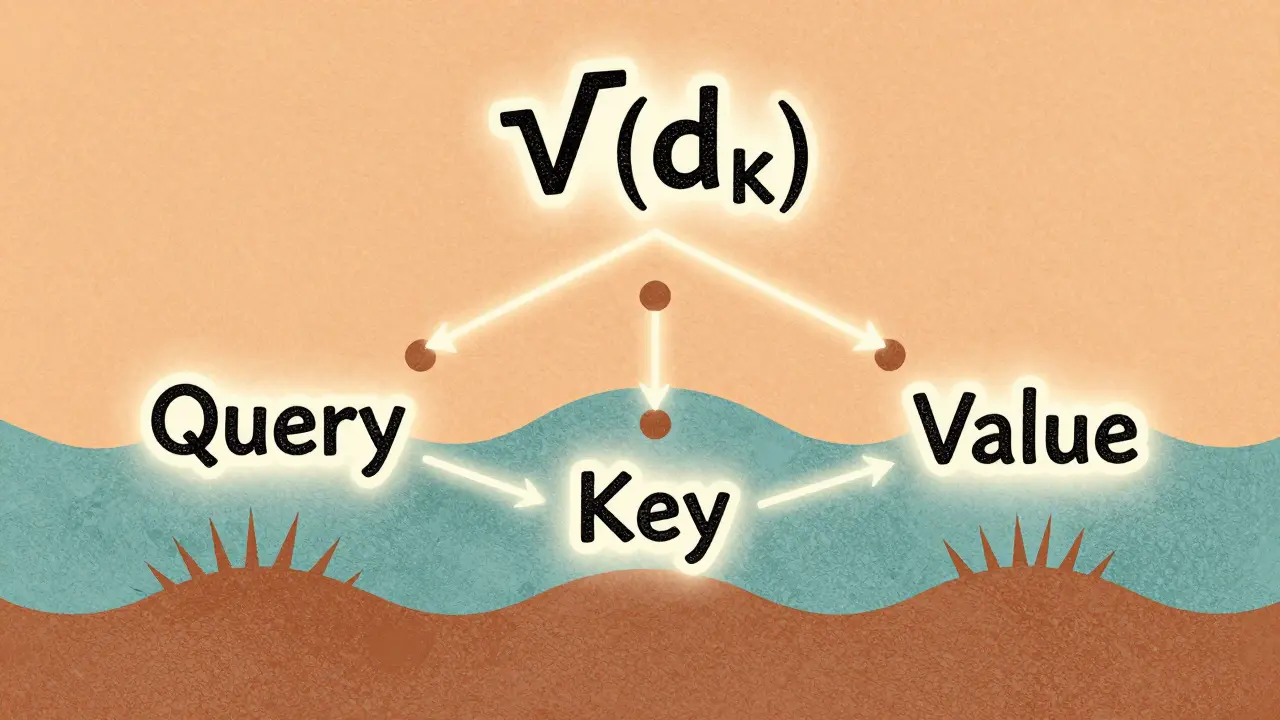
Scaled Dot-Product Attention Explained for Large Language Model Practitioners
Scaled dot-product attention is the core mechanism behind modern LLMs like GPT and Llama. Learn why the 1/√(d_k) scaling is non-negotiable, how it prevents training collapse, and what pitfalls to avoid in practice.
Read More
Multi-Head Attention in Large Language Models: How Parallel Perspectives Power Modern AI
Multi-head attention lets large language models understand language from multiple angles at once, enabling breakthroughs in context, grammar, and meaning. Learn how it works, why it dominates AI, and what's next.
Read More