Imagine you are waiting for a reply from an AI assistant. It stares at the screen for three full seconds before printing the first word. Then, it types out the rest of the answer instantly. Or imagine the opposite: the first word appears immediately, but each subsequent letter takes half a second to load. Which experience feels better? Most people would choose the instant start, even if the total time is longer. This simple preference highlights the core engineering battle in Large Language Model (LLM) serving: throughput versus latency.
These two metrics often pull in opposite directions. Optimizing one usually hurts the other. Understanding why this happens requires looking under the hood of the transformer architecture and how modern hardware handles the math behind language generation.
The Core Metrics: What Are You Actually Measuring?
To navigate this tradeoff, we need precise definitions. Vague terms lead to bad decisions.
Throughput is the number of output tokens generated per second across all users and requests on a server. Think of it as the factory’s production rate. High throughput means your GPU is working hard, processing many requests simultaneously. This directly lowers your cost per token because you are squeezing more value out of expensive hardware like NVIDIA A100 or H100 GPUs.
Latency is the end-to-end time a user waits for a response. But latency isn’t just one number. It breaks down into two critical parts:
- Time To First Token (TTFT): The delay between when you hit "Enter" and when the first character appears. This is crucial for user perception. If TTFT is high, users assume the system is broken or slow.
- Time Per Output Token (TPOT): The time it takes to generate each subsequent token after the first one. This affects the smoothness of the reading experience.
Total latency equals TTFT plus (TPOT multiplied by the number of output tokens). A common mistake is averaging latency across all requests. Averages hide the truth. If 90% of your users get fast responses but 10% wait forever, your average looks good, but those 10% will churn. We care about percentiles, specifically the 95th or 99th percentile latency.
The Prefill-Decode Divide: Why Batching Is Tricky
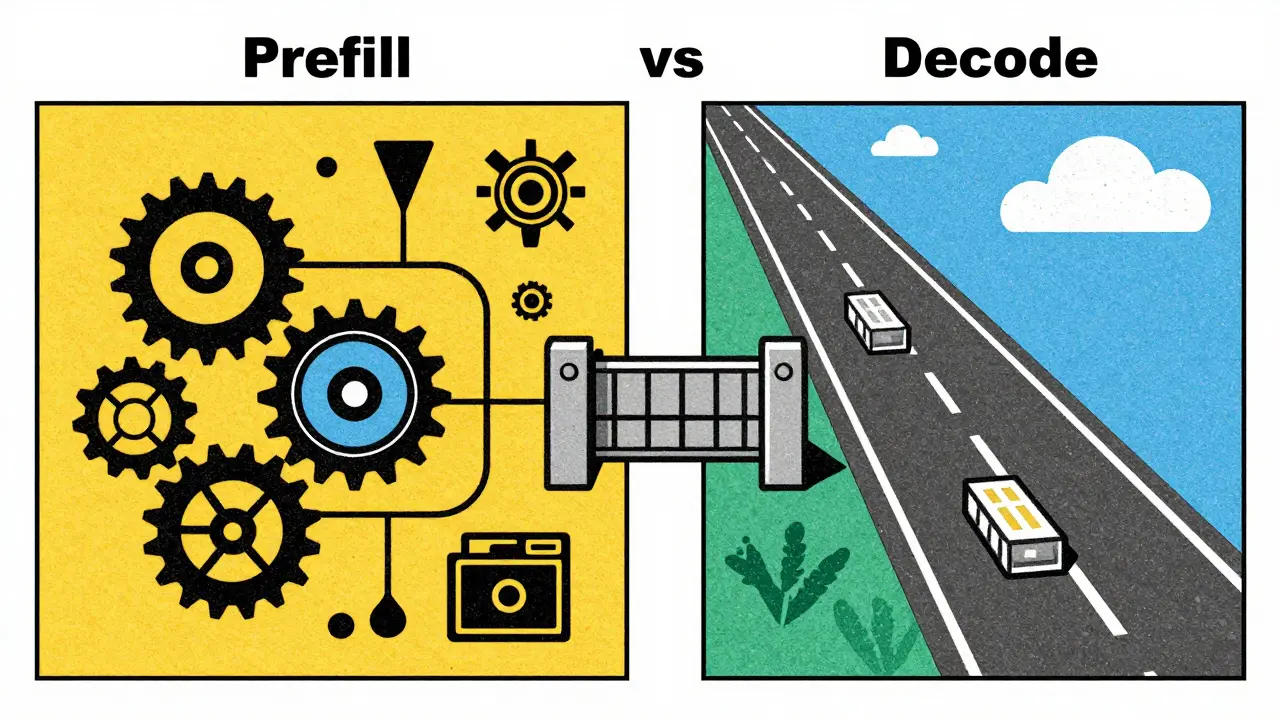
The reason throughput and latency fight each other lies in how transformers process data. Inference happens in two distinct phases: prefill and decode. They have completely different computational needs.
Prefill phase is the initial step where the model processes the entire input prompt to create context embeddings. During prefill, the GPU is compute-bound. It has plenty of work to do-calculating attention scores for every token in the prompt against every other token. Because the workload is so heavy, adding more requests to a batch doesn’t help much. Even with a single request, the GPU cores are fully saturated. Prefill throughput maxes out quickly regardless of batch size.
Decode phase is the iterative process of generating one token at a time based on previous context. Here, the situation flips. Generating a single token involves very little computation but requires fetching massive amounts of model parameters from memory. This makes decoding memory-bandwidth bound. At low batch sizes, the GPU spends most of its time waiting for data. By increasing the batch size, you amortize the cost of fetching weights across multiple requests. Decode throughput increases almost linearly with batch size until you hit the limit of your memory bandwidth.
This difference creates the bottleneck. If you use small batches to keep TTFT low (fast prefill), your decode phase underutilizes the GPU, killing throughput. If you use large batches to maximize throughput, new requests must wait in line while long-running decodes finish, spiking TTFT.
| Phase | Primary Constraint | Batching Impact | Optimization Goal |
|---|---|---|---|
| Prefill | Compute (GPU Cores) | Low (saturates quickly) | Reduce TTFT |
| Decode | Memory Bandwidth (HBM) | High (linear increase) | Maximize Throughput |
Scheduling Strategies: Who Gets Priority?
Since hardware can’t magically do both perfectly, software scheduling becomes the deciding factor. How does the inference engine decide which request to run next?
Traditional systems used request-level batching. A batch starts, runs through prefill and decode, and finishes entirely before new requests enter. This guarantees low TTFT for the current batch but leads to terrible throughput because the GPU sits idle during gaps between batches. Systems like FasterTransformer historically struggled here.
Modern engines like vLLM use iteration-level batching with techniques like PagedAttention. They allow new requests to join the decode loop dynamically. However, they still face a choice: prioritize prefills or prioritize decodes?
Prefill-prioritizing schedules are scheduling policies that interrupt ongoing decodes to process new incoming prompts, minimizing TTFT. This keeps users happy with instant responses. But constantly stopping and starting decodes adds overhead and can reduce overall throughput.
Decode-prioritizing schedules are policies that let running decodes finish without interruption, maximizing GPU utilization and throughput. This is cheaper for the provider. But new users wait longer for their first token. If a long query is decoding, short queries queue up, causing TTFT spikes.
Research systems like Sarathi-Serve attempt to tame this tradeoff by intelligently interleaving these phases. On an NVIDIA A100 GPU, Sarathi-Serve demonstrated up to 2.6x higher throughput for Mistral-7B within strict latency Service Level Objectives (SLOs) compared to standard vLLM configurations. For larger models like Falcon-180B distributed across eight GPUs, the improvement jumped to 6.9x. This proves that smart scheduling can shift the Pareto frontier, giving you more performance for the same hardware cost.
Tensor Parallelism: The Cost of Scaling Out
When a model is too big for one GPU, engineers use tensor parallelism. This splits the model’s layers across multiple GPUs. While this enables running massive models, it introduces a hidden tax on efficiency.
In tensor parallelism, linear layers are partitioned across devices. After each layer, the partial results must be combined using all-reduce operations. This communication happens twice per transformer layer: once after the attention mechanism and once after the multilayer perceptron (MLP).
Here is the catch: the amount of data communicated depends on the sequence length and hidden dimension, not on how many GPUs you add. So, if you double the GPUs, you halve the computation per GPU, but the communication volume stays the same. This increases the communication-to-compute ratio.
As you scale out, a larger fraction of inference time is spent moving data between GPUs rather than calculating tokens. This degrades both latency scalability and throughput efficiency. For example, while tensor parallelism reduces TTFT for huge models like Llama2-70B by speeding up the prefill phase, it can significantly drop throughput per GPU due to network congestion. You pay more for infrastructure but don’t get proportional gains in speed.
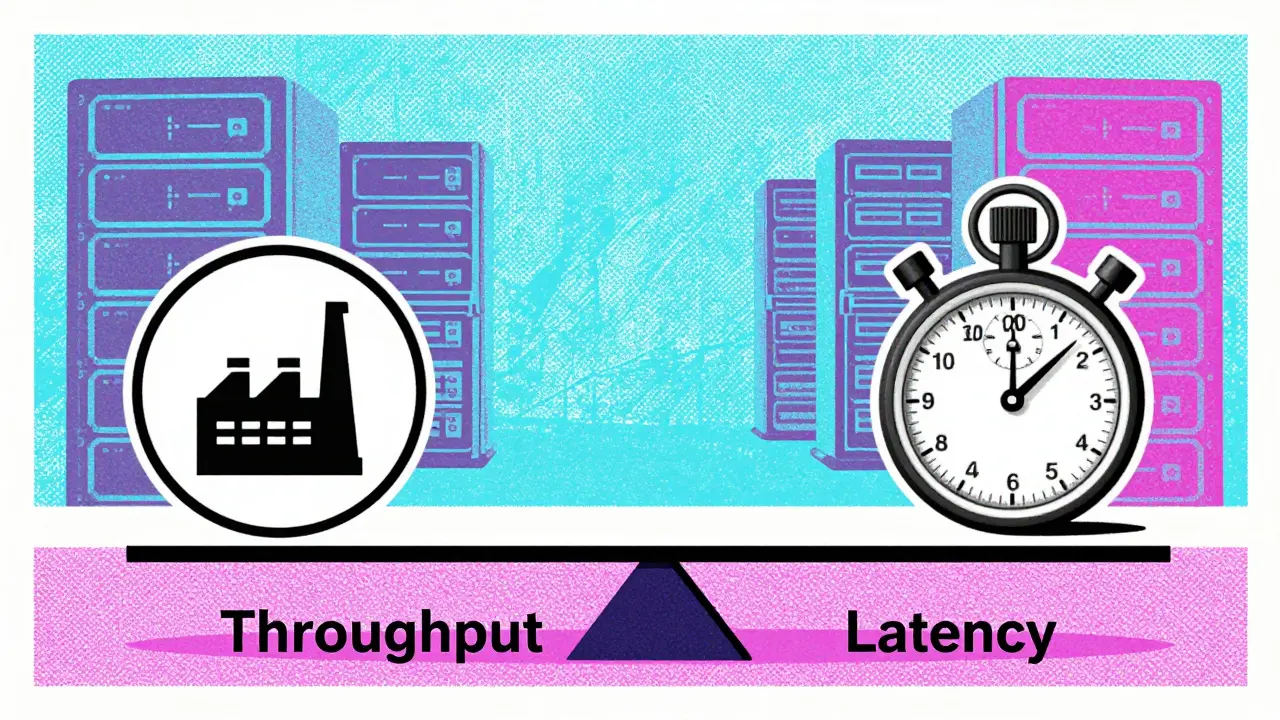
Choosing Your Strategy Based on Use Case
There is no universal best setting. Your optimal point on the throughput-latency curve depends entirely on your application type.
If you are building a chatbot or a code editor plugin, Interactive applications require low TTFT and consistent TPOT to maintain user engagement. Users expect immediate feedback. Here, Quadrant II performance (low TTFT, moderate throughput) is ideal. You might accept lower GPU utilization to ensure no user waits more than 200 milliseconds for the first token. Frameworks should be configured with smaller batch sizes or prefill-prioritizing schedulers.
If you are processing bulk data, such as summarizing thousands of documents overnight, Batch processing workloads prioritize maximum throughput and lowest cost per token. Latency doesn’t matter as much. You want to push the GPU to its limits. Use large batch sizes, decode-prioritizing schedules, and perhaps sacrifice TTFT to keep the pipeline full. This is Quadrant III behavior (high throughput, higher latency).
Avoid Quadrant I at all costs: high TTFT and low throughput. This usually indicates overloaded hardware, inefficient batching, or poor memory management. It’s the worst of both worlds-slow for users and expensive for you.
Practical Steps to Optimize Your Stack
So, what can you do right now? Here is a checklist for tuning your inference setup:
- Instrument Everything: Don’t guess. Log prompt arrival, prefill completion, and each token emission. Calculate TTFT, TPOT, and Goodput (SLO-compliant outputs per second) separately.
- Test Batch Sizes Aggressively: Run benchmarks with batch sizes of 1, 4, 16, 32, and 64. Plot TTFT against throughput. Find the knee of the curve where latency spikes disproportionately.
- Choose the Right Engine: For interactive apps, consider engines with dynamic batching like vLLM or TGI. For pure throughput, look into specialized schedulers like Sarathi-Serve if available, or tune vLLM’s scheduler settings.
- Monitor Memory Bandwidth: Use tools like `nvtop` to check if your GPU is compute-bound or memory-bound during decode. If memory-bound, increasing batch size helps. If compute-bound, it won’t.
- Re-evaluate Tensor Parallelism: Only use TP if necessary. Pipeline parallelism might offer better throughput characteristics for some models. Measure the communication overhead before scaling out.
The landscape of LLM inference is evolving rapidly. New architectures like Ulysses aim to optimize communication patterns further. But the fundamental tension remains: hardware resources are finite, and users demand speed. By understanding the mechanics of prefill, decode, and scheduling, you can make informed tradeoffs that align with your business goals.
What is the difference between TTFT and TPOT?
TTFT (Time To First Token) measures the delay from sending a request to receiving the first generated token. It reflects the prefill phase speed. TPOT (Time Per Output Token) measures how long it takes to generate each subsequent token during the decode phase. TTFT impacts perceived responsiveness, while TPOT impacts the smoothness of the streaming experience.
Why does increasing batch size improve throughput but hurt latency?
In the decode phase, GPUs are limited by memory bandwidth, not compute power. Larger batches allow the system to amortize the cost of loading model weights across more requests, improving efficiency. However, larger batches mean new requests must wait longer for the GPU to finish processing existing ones, increasing TTFT.
Is vLLM better than FasterTransformer?
For most general-purpose LLM serving tasks, vLLM is currently superior due to its PagedAttention mechanism, which manages memory more efficiently and supports dynamic batching. FasterTransformer is highly optimized for specific fixed-batch scenarios but lacks the flexibility for variable-length requests common in chat applications.
How does tensor parallelism affect inference speed?
Tensor parallelism reduces latency for the prefill phase by distributing computation across multiple GPUs. However, it increases communication overhead via all-reduce operations, which can degrade throughput and increase latency during the decode phase if the network bandwidth is insufficient.
What is Goodput in LLM inference?
Goodput measures the number of outputs that meet specific Service Level Objectives (SLOs) per second. Unlike raw throughput, which counts all tokens, goodput filters out requests that failed to meet latency or quality targets, providing a more accurate metric of effective system performance for users.