On-Prem LLM: Run Large Language Models Locally with Control and Security
When you run a on-prem LLM, a large language model hosted and operated entirely within your own infrastructure, not on a public cloud. Also known as local LLM, it gives you full control over data, costs, and performance—critical for healthcare, finance, and government work where privacy isn’t optional. Unlike cloud-based AI services that send your prompts to remote servers, an on-prem LLM processes everything inside your firewall. That means no third party sees your customer data, internal documents, or proprietary prompts.
This approach isn’t just about security—it’s about reliability. If your internet goes down, your AI still works. If the cloud provider changes pricing or shuts down a model, you’re not stuck. You own the hardware, the weights, and the inference pipeline. That’s why companies like banks, law firms, and defense contractors are shifting from OpenAI’s API to models like Llama 3, Mistral, or Phi-3 running on NVIDIA DGX servers or even custom-built rigs with 8x H100 GPUs. The trade-off? You need strong IT teams, good cooling, and upfront investment. But for many, that’s cheaper than paying per token for years.
Running an on-prem LLM also ties into other key concepts like confidential computing, hardware-based protection that encrypts data even while it’s being processed. This lets you use Trusted Execution Environments (TEEs) from Intel SGX or AMD SEV to shield model weights and user inputs from system admins, cloud providers, or even malware. It’s not just about keeping data out of the cloud—it’s about keeping it safe even inside your own data center. Then there’s LLM deployment, the full lifecycle of getting a model from training to serving real users. On-prem means you handle quantization, caching, autoscaling, and monitoring yourself. Tools like vLLM, TensorRT-LLM, and Hugging Face’s TGI make this easier than ever, but you still need to plan for GPU memory, batch sizes, and latency targets.
You’ll also find that on-prem LLMs work best when paired with retrieval-augmented generation, a technique that pulls in your own internal documents to ground the model’s answers. Why? Because a local model doesn’t magically know your company’s policies, product specs, or legacy databases. RAG lets you connect it to your internal vector stores—without sending any of that data outside. This combo—on-prem LLM + RAG—is becoming the gold standard for enterprises that need accuracy, compliance, and zero data leakage.
What you’ll find in the posts below are real-world breakdowns of how teams actually deploy these systems. You’ll see how to secure model weights, cut inference costs with quantization, monitor GPU usage in production, and avoid vendor lock-in while still using cutting-edge models. No fluff. No hype. Just the tactics that work when your business depends on keeping AI inside your walls.
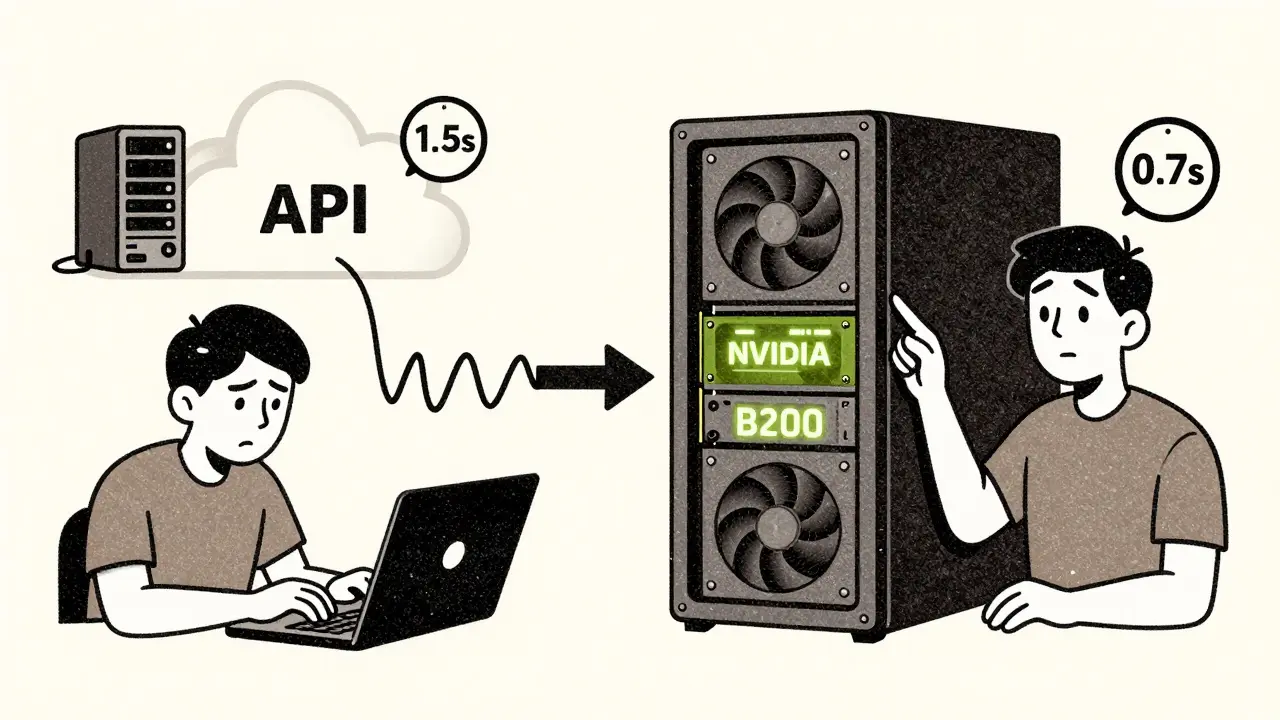
Latency and Control Tradeoffs: API LLMs vs On-Prem Deployment
Choosing between API-based LLMs and on-prem deployment affects latency, data control, cost, and scalability. Learn when to use each-and how top companies combine both for optimal results.
Read More
Hybrid Cloud and On-Prem Strategies for Large Language Model Serving
Learn how to balance cost, security, and performance by combining on-prem infrastructure with public cloud for serving large language models. Real-world strategies for enterprises in 2025.
Read More