
Have you ever asked an AI a question and it answered perfectly - even though you didn’t train it? That’s not magic. It’s in-context learning. This is how modern large language models like GPT-4, Llama 3.1, and Claude 3 figure out what you want just by seeing a few examples in your prompt. No retraining. No tweaking weights. Just input, examples, and output - all in one go.
What Exactly Is In-Context Learning?
In-context learning (ICL) is the ability of a pre-trained language model to perform a new task by seeing just a few examples inside the prompt you send it. You don’t change a single parameter in the model. You don’t run another round of training. You simply show it what you want, and it follows along.
Think of it like giving someone a cheat sheet before a test. You don’t teach them the whole subject - you just show them a couple of solved problems, and they figure out the pattern. That’s ICL. It was first clearly demonstrated in 2020 by OpenAI’s GPT-3 paper, Language Models are Few-Shot Learners. Before that, AI needed hundreds or thousands of labeled examples to learn a new task. Now, sometimes, just one or two are enough.
How Does It Work? The Mechanics Behind the Magic
LLMs are trained on massive amounts of text - books, articles, code, forums - so they learn patterns, grammar, and even reasoning structures. But they’re not just memorizing. They’re building internal models of how language works.
When you give an LLM a prompt like:
- Input: "The movie was great." → Output: "Positive"
- Input: "This film bored me to tears." → Output: "Negative"
- Input: "I loved every minute." → Output: ?
The model doesn’t just match words. It detects a pattern: sentiment classification. It recognizes that you’re asking it to label tone, not count words. And then it applies that same logic to the new input.
Research from MIT in 2023 showed something surprising: LLMs can learn tasks using synthetic examples - made-up data they’ve never seen before. That means they’re not just copying from training data. They’re building a mini learning system inside their layers.
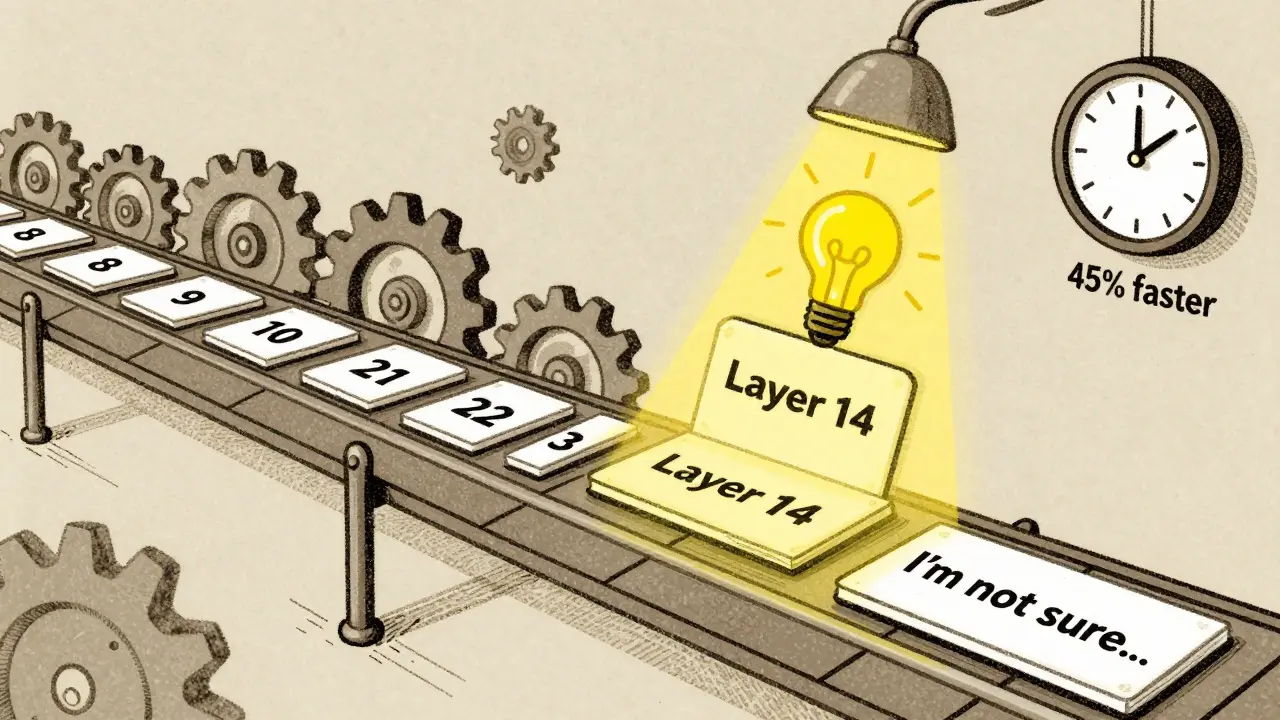
One study using models like GPTNeo2.7B and Llama3.1-8B found that around layer 14 of 32, the model "gets it." That’s the point where it stops relying on the examples and starts applying the learned task internally. After that, it can ignore the context and focus on the new input. This discovery lets systems skip processing the full prompt after that layer - saving up to 45% of computation.
Why It Beats Traditional Methods
Before ICL, there were two main ways to adapt models:
- Supervised fine-tuning: You need new labeled data, run training, update weights, and redeploy. Takes days.
- Zero-shot learning: You give no examples. Just say, "Classify this sentiment." Accuracy? Often 30-40%.
ICL sits between them. With zero examples, you get 35% accuracy. With one example, it jumps to 45%. With 5-8 well-chosen examples? You hit 70-80% accuracy on many tasks.
And here’s the kicker: ICL is faster and cheaper. A McKinsey survey in late 2023 found that companies using ICL to adapt models took an average of 2.3 days to deploy. Fine-tuning? 28.7 days. That’s why 68% of enterprises now prefer ICL over parameter updates.

Real-World Use Cases You Can See Today
ICL isn’t just research. It’s running in production right now:
- Customer service chatbots: 78% of enterprises use ICL to handle common questions without retraining. Show the model a few sample conversations, and it handles new ones.
- Medical record analysis: Doctors upload anonymized notes. The model learns to flag risks - like possible drug interactions - from just three examples.
- Legal document summarization: Law firms feed it past case summaries. The AI learns to extract key rulings without needing legal training.
- Financial reporting: 42% of finance teams use ICL to auto-generate earnings summaries from raw data. One bank cut report prep time from 12 hours to 45 minutes.
IBM’s research showed an 80.24% accuracy rate on aviation incident classification using just eight examples. That’s better than some human analysts.
What Doesn’t Work? The Limits of ICL
ICL isn’t magic. It has clear boundaries.
- Context window limits: Most models handle 4K-128K tokens. If your examples are too long, you lose them. Some models start dropping earlier examples when you add more than 32.
- Prompt sensitivity: Change one word - "Classify this" to "Tell me if this is positive" - and performance can drop 15%. Small wording shifts matter.
- Task type matters: ICL excels at classification, translation, and pattern matching. It struggles with tasks requiring deep domain knowledge - like interpreting a new medical study or predicting stock trends.
- Example quality: Random examples hurt performance. Pick ones that are clear, varied, and representative. One study showed a 25% accuracy boost just by swapping out weak examples.
And here’s the twist: More examples don’t always mean better results. After 8-16 examples, gains fade. Sometimes, adding more confuses the model.
How to Do It Right: Pro Tips for Prompt Engineering
If you want ICL to work well, you need to engineer your prompts smartly:
- Start with 2-5 examples. Don’t overload. Test with 1, 3, 5. See where accuracy plateaus.
- Use chain-of-thought. For reasoning tasks, show your work. Example: "The price dropped 20%. That’s $40 off $200. So final price is $160." This boosted math problem accuracy in GPT-3 from 18% to 58%.
- Order matters. Put harder examples first. One sentiment analysis test showed a 7.3% improvement when the most ambiguous case was shown before the simple ones.
- Be consistent. Use the same format: "Input: ... → Output: ..." every time. Switching formats breaks the pattern.
- Use natural language. Don’t code in JSON or XML unless you have to. Models understand sentences better than structured data.
The Big Debate: Is This Real Learning?
Are LLMs actually learning? Or are they just really good at guessing?
Yann LeCun, AI pioneer at Meta, argues ICL isn’t learning - it’s pattern matching on steroids. He says the model is just retrieving and remixing what it saw during training.
But MIT’s Ekin Akyürek proved otherwise. His team gave LLMs synthetic tasks with no training data overlap - and the models still performed. That suggests something deeper is happening.
Some researchers think it’s meta-learning: the model learned how to learn during pretraining. Others think it’s Bayesian inference: the model updates its internal belief about the task based on evidence. A third theory says it’s task composition: the model combines pre-learned skills to form a new one.
Truth? We don’t fully know yet. But we do know it works - and it’s getting better.
What’s Next? The Future of In-Context Learning
ICL is evolving fast:
- Bigger context windows: Anthropic’s Claude 3.5 is aiming for 1 million tokens by late 2024. That means hundreds of examples - not just a handful.
- Smarter examples: New tools are emerging that automatically pick the best examples from your data. One system reduced needed examples from 8 to 3 without losing accuracy.
- Warmup training: A new technique fine-tunes models briefly on prompt-like examples before inference. It boosted performance by 12.4% across 10 benchmarks.
- Instruction tuning: Training models on thousands of task instructions (like "Summarize this" or "Translate to French") improved zero-shot and few-shot results by 18.7%.
Gartner predicts that by 2026, 85% of enterprise AI apps will use ICL as their main way to adapt - not fine-tuning. That’s because it’s fast, cheap, and doesn’t require data pipelines or GPU time.
By 2030, ICL won’t be a feature. It’ll be the default. The way we talk to AI won’t be through training - it’ll be through conversation. And that’s exactly what in-context learning is: a conversation, not a command.
Can in-context learning replace model fine-tuning entirely?
Not always. ICL is great for quick, low-cost adaptations - like changing a chatbot’s tone or handling new customer questions. But for tasks requiring deep, consistent expertise - like legal compliance or medical diagnosis - fine-tuning still delivers higher reliability. Many teams use both: ICL for rapid iteration, fine-tuning for mission-critical tasks.
How many examples do I need for in-context learning?
Start with 2-5. Most tasks peak in accuracy between 5 and 8 examples. Beyond 16, performance often drops due to context overload. The sweet spot? Test 1, 3, 5, and 8. You’ll usually find that 3-5 examples give you 90% of the gain.
Why do some prompts work and others don’t?
It’s all about pattern clarity. If your examples are inconsistent - some use "Yes/No," others use "Positive/Negative," or you mix formats - the model gets confused. Also, vague examples like "This is good" without context won’t help. Be specific. Show the input, show the output, and keep the structure identical across all examples.
Does in-context learning work on all LLMs?
Most modern LLMs support it - GPT-3.5+, Llama 2+, Claude 2+, and Gemini 1.5 all do. But performance varies. Models trained with instruction tuning (like Llama 3.1) handle ICL better than older ones. Also, smaller models (under 7B parameters) struggle with complex tasks. Stick to 13B+ models for reliable results.
Can I use in-context learning with non-text data?
Not directly. ICL works with text. But you can convert other data into text. For example, turn a spreadsheet into a list of rows: "Row 1: Customer A, spent $120, returned item → Label: High Value. Row 2: Customer B, spent $15, no returns → Label: Low Value." Then feed that text to the model. This is how many teams use ICL for tabular data, images (via captions), and even audio (via transcripts).




ANAND BHUSHAN
20 March, 2026 - 18:40 PM
In-context learning is wild when you think about it. You throw in a couple of examples and suddenly the model just gets it. No training, no fuss. It’s like handing someone a recipe and they start cooking like a chef. I’ve used it for simple classification tasks and it’s saved me hours.
Still, I’m cautious. Sometimes it works too well and you forget it’s not actually learning. Just pattern matching. But hey, if it works, who cares?
Indi s
21 March, 2026 - 09:21 AM
This is exactly why I stopped trying to fine-tune models. I used to spend days labeling data, training, testing - and then the model still messed up edge cases.
Now I just give it 3 clean examples and move on. It’s faster, cheaper, and honestly, less frustrating. The real win is not having to manage data pipelines anymore.
Rohit Sen
22 March, 2026 - 15:04 PM
Let’s be real - this isn’t learning. It’s advanced autocomplete with a PhD. The model isn’t understanding anything. It’s just recalling fragments from its training and stitching them together like a collage.
People call it magic. I call it statistical hallucination with a fancy name.
Vimal Kumar
24 March, 2026 - 12:47 PM
I love how this makes AI accessible. You don’t need to be a data scientist to make models work. I showed a junior teammate how to use ICL last week - they built a customer support filter in 20 minutes.
That’s the real power. Not the tech, but how it lowers the barrier. Anyone with a clear example can make it work. No PhD required.
Amit Umarani
24 March, 2026 - 19:41 PM
Incorrect punctuation in the example prompt: 'Input: "The movie was great." → Output: "Positive"' - the arrow should be a proper Unicode →, not an ASCII ->. Also, inconsistent spacing around the arrow in some examples. These small errors reduce performance.
And why are you using "I loved every minute." as a positive example? That’s not even grammatically standard. Should be "I loved every minute." with a period. Amateur hour.
Noel Dhiraj
26 March, 2026 - 12:29 PM
Just tried this with a legal doc summarizer at work. Gave it 4 examples. Boom - started pulling out clauses like a paralegal. No training, no API calls, no cost.
My boss thought I was lying. Then he saw the output. Now he’s asking for 10 more use cases. I’m just happy I don’t have to babysit a fine-tuned model anymore.
vidhi patel
28 March, 2026 - 03:43 AM
It is imperative to note that the assertion that in-context learning constitutes genuine learning is scientifically untenable. The model does not possess cognitive capacity. It is a stochastic parrot. The claim that it "understands" sentiment or task structure is a dangerous anthropomorphization.
Furthermore, the cited MIT study lacks peer-reviewed validation. I demand citations from Nature or Science before accepting such claims.
Priti Yadav
28 March, 2026 - 18:09 PM
Wait - you’re telling me these models just guess based on examples? So what’s to stop Big Tech from feeding them biased data and making them spit out lies that look like truth?
What if the "examples" are planted? What if they’re not even real? This feels like a controlled illusion. I’m not trusting any AI that learns from prompts. That’s how propaganda spreads.
Ajit Kumar
30 March, 2026 - 04:49 AM
While the general premise of in-context learning is superficially compelling, one must interrogate the underlying assumptions with rigor. The notion that a language model can "learn" a task from context presumes an ontological equivalence between human cognition and statistical inference - a fallacy of category error.
Moreover, the cited 45% computation savings are predicated on an unverified hypothesis regarding layer 14 as the "epiphany point." No formal ablation study is referenced. One must question the validity of such claims when they are not accompanied by rigorous empirical validation, especially given the proliferation of cherry-picked benchmarks in the field.
Additionally, the suggestion that natural language is preferable to structured formats ignores the fact that structured formats preserve syntactic fidelity, whereas natural language introduces ambiguity - a fundamental flaw in reproducibility. The assertion that "models understand sentences better than structured data" is not only unsupported, it is demonstrably false in controlled settings.
Finally, the claim that "ICL isn’t magic" is itself magical thinking. It is, in fact, magic - but magic rooted in probability distributions, not intelligence. To pretend otherwise is to engage in technobabble that obscures more than it elucidates.
Diwakar Pandey
31 March, 2026 - 00:51 AM
One thing I’ve learned from using ICL for customer feedback analysis: the order of examples matters way more than people admit.
I had a model consistently misclassifying sarcastic comments as positive. Turned out I put the easy, literal examples first. When I flipped it - started with the tricky ones - accuracy jumped from 62% to 84%.
Also, don’t use "good" or "bad" as outputs. Use "Positive" and "Negative". Consistency is everything. I learned this the hard way after 3 failed deployments.
And yeah, 3-5 examples is the sweet spot. More than that and it starts overthinking. Less and it’s just guessing.