Tag: transformer attention
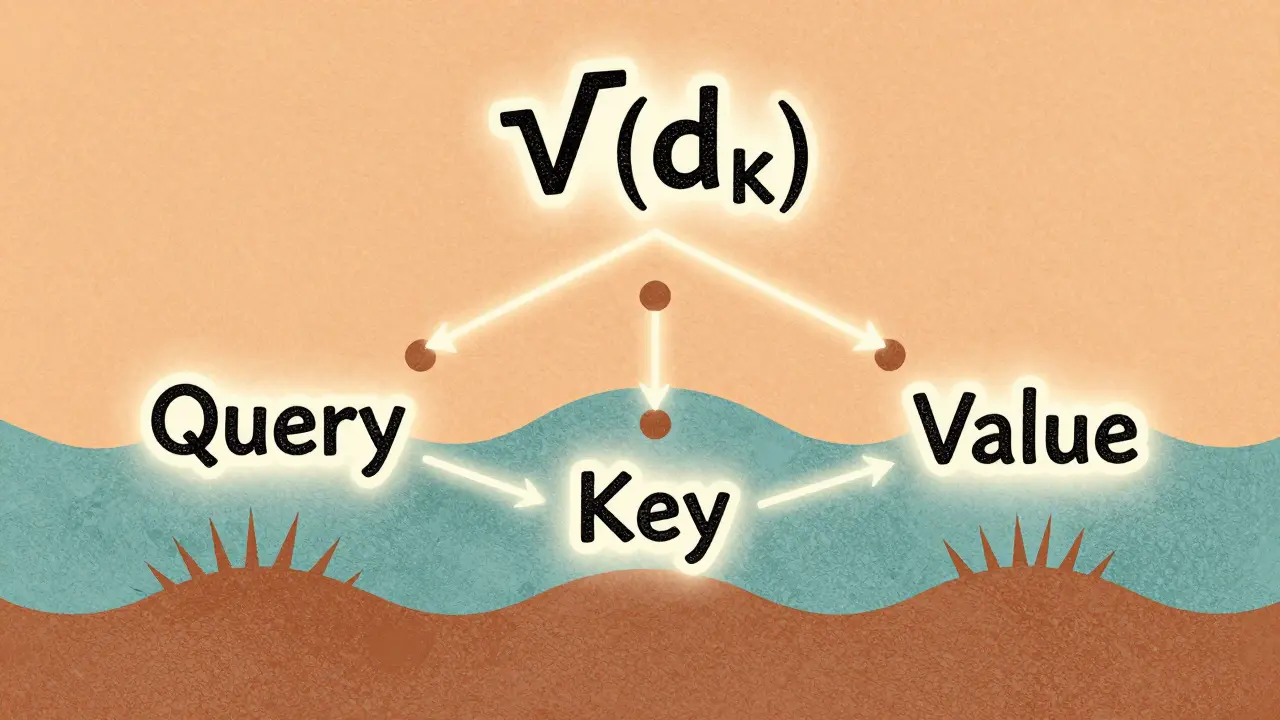
Scaled Dot-Product Attention Explained for Large Language Model Practitioners
Scaled dot-product attention is the core mechanism behind modern LLMs like GPT and Llama. Learn why the 1/√(d_k) scaling is non-negotiable, how it prevents training collapse, and what pitfalls to avoid in practice.
Read More